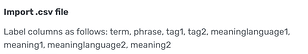The information filling the new words comes from a database, but the results are limited to checking the first 200 words.
Solution for new words
You can use this below link to get word data from your lesson. In this example we are looking at the new words. For your own lesson you need to change the country from ‘fi’ and the 2251… to your lesson id. (long number at end of LingQ URL which is the ID for your lesson)
The page that opens is a JSON file. (A text file filled with structured information)
Press save and download it. Now we use a Python script to find the information we want.
Python Script
import json
# Open the JSON file
with open('newword.json', 'r') as file:
data = json.load(file)
# Go through the JSON data
for key in data['words']:
# Check if the status is 'new'
if data['words'][key]['status'] == 'new':
# Print the text field
print(data['words'][key]['text'])
This will print a copy-able list of all new words in the lesson.
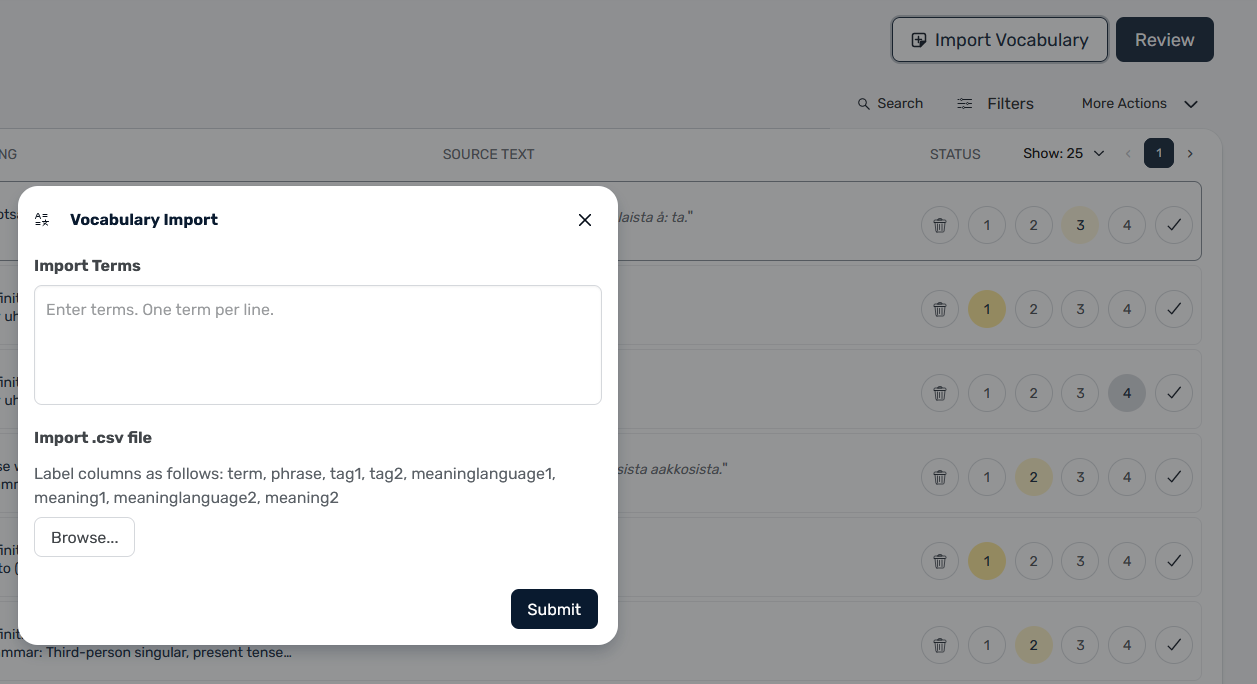
We now want to fill out some information for these words and return them in a format ready to be uploaded to LINGQ.
plug in the format you want and words list into GPT.
GPT 4 LingQ Format Example
GPT-4
Here is my example slides spreadsheet with 6 columns. The last 2 columns are unused.
term phrase meaninglanguage1 meaning1 meaninglanguage2 meaning2 lensit ...lensit korkealle... en Definition: you flew; Grammar: second-person singular, past tense. Base word: lentää (to fly) "Lensit korkealle." "You flew high." tähtiin ...katsoin tähtiin... en Definition: to the stars; Grammar: illative plural form. Base word: tähti (star) "Katsoin tähtiin." "I looked at the stars."
Please fill out the information in the format like my example for the below words
@roosterburton Would there be a way to do this on a large scale? That is, for the most common 50k or 100k word tokens? In other words, pretty much creating and importing a dictionary.
Yes I could write some code to do that, main factor would be cost. The bastards only give established companies access to the GPT 4 API but I could set something up that returns basically an entire language definitions with GPT-3.5.
You could add some extra checks get it to double check its results or w/e buts its just adds to cost. Wouldnt be very expensive with GPT 3.5 probably $50-$100 for an entire language.
@roosterburton For an individual, it would just be cheaper to buy a bilingual dictionary for idk $10 or something. For LingQ as a company though, as they wouldn’t be willing to pay for a kajillion licences of the dictionary, this could potentially be the cheapest way to build reliable dictionaries for a minimum cost. Perhaps consider proposing the idea to North or Mark on the Librarian’s chat.
Probably someone is doing it, but you have to find it, right? The issue for LingQ is that it’s used for commercial purposes with lots of people, so they can’t get a normal dictionary in such a format, as this requires lots of licences, which costs a lot more money than $100 per language.
For those who are interested, I’ve been playing with this a bit myself.
I increased the ‘chunk_size’ of the link @roosterburton posted, as my lessons were longer.
I then had a chat, which I set up to check if the list of words were real words (i.e. filter out any proper nouns, misspellings, and unknown words). My prompt was this:
Here is a list of words in Italian. Remove any words which are proper nouns, misspellings, or unknown words. Give me the list of remaining Italian words. Do not change the spelling of any word. Do not give them as dot points. Tell me how many words you removed.
fingo
discorrendo
…
Then I had another chat to write the definitions. I’m not too happy with my prompt, so I won’t share it. It was writing definitions, but often not 100% accurate.
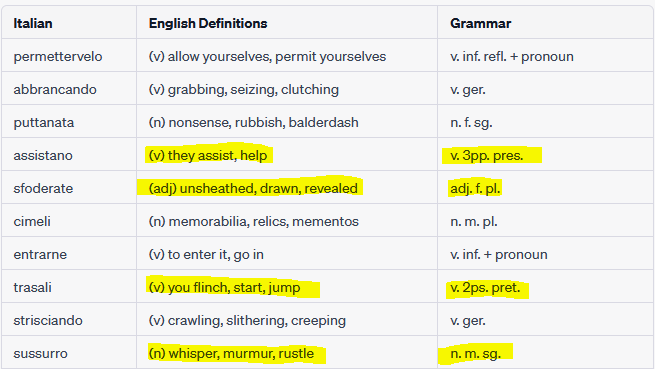
For example:
These four definitions are mostly accurate, but not completely:
‘assistano’ is third person subjective present
‘sfoderate’ is also past participle and second person plural present
‘trasali’ is not actually a word. The second person singular present conjugation is ‘trasalisci’
‘sussuro’ is also first person present as a verb
I merely had the second grammar column as a way to check if the definition was correct. I only imported the Italian words and the English definitions.
All in all, as a way to add defintions, this could work. It takes plenty of time to set up a correct prompt though, which was annoying. Furthermore, it takes time to do it, but it’s much faster after you’ve already got everything set up. I think a better prompt would yield better results than what I’m getting. Or adding in a double-check. It would also be language dependent on how well it works. Ideally, though, LingQ would already have good definitions, which can be accessed in one click.
This is a damn fine idea to add a prompt. Nice work. I don’t know any Italian… but why remove the nouns from the response?
The current structure for LINGQs may be getting updated. But currently we need to use these fields to import. I think tag1/2 is like Noun/Verb/Pronoun etc, but they are not very well defined and you dont need them to import.
Would this require a redesign of the UI?
Yes. And probably slightly painful on the backend too.
(I had a look at how LINGQs are created, I was looking into an extension that auto fills blue cards with the most popular meaning when you click finish lesson and the cards are saved in a giant pile like 40 mill cards sitting in a stack from what I remember.)
I only remove proper nouns. I don’t care about writing definitions of what would be people’s names, etc. It just gives ChatGPT more space to write wrong definitions. Unfortunately, my prompt isn’t enough to stop all nonsense words. There are still some, which end up coming through. Eg. the word ‘matata’ from ‘hacuna matata’. ChatGPT even wrote a definition for it… “(adj) muddled, mixed up, confused” which is obviously completely false and made-up.
I just had a spreadsheet open, with these headings. I would copy the whole thing in the spreadsheet and just move the definition to the correct column. Less that ChatGPT has to do, the less mistakes it can make.
I don’t think it would require a whole UI redesign. I think if LingQ just creates a quality dictionary for each language (or at least a few of the main ones), then make these definitions the top definition in the list, it wouldn’t require any change. Then you just turn on ‘auto-lingQ on click’ (which takes the top definition) and it would function great. This would be better, because then the word would remain blue until you click it the first time, which works fine for the statistics, and also the visuals (a blue word means a word never encountered before).
I have noticed over large amounts of testing that it likes to set the grammar based on how the word is used in a phrase, even if it doesn’t give you that phrase. ‘matata’ might be used somewhere as Italian in a different phrase in the context meaning that. If you ask GPT to first define a word ask for a phrase too. This way it atleast puts some sort of classification to its apparent madness.
Try open a new chat window for every request you make, It gets very lost after a short while due to browser memory limitations.
I may have done this for a sort-of unsupported language (Low German), my specific issue here was there are 3-4 written standards (depending on how you count Plattdietsch – American Low German), and most people don’t follow any of them . But even with that issue, having ~20K pre-loaded LingQs made everything more readable.
I don’t think it would require a whole UI redesign. I think if LingQ just creates a quality dictionary for each language (or at least a few of the main ones), then make these definitions the top definition in the list, it wouldn’t require any change.
The issue here I presume is licensing & copyright. It’s very different for LingQ to provide a link to a dictionary and let us copy and save a definition than it is for LingQ to save that content itself and serve it to us. I think it could be argued on its own that people sharing their own definitions is an issue, but I am not a lawyer.
@noxialisrex The idea is for LingQ to create the dictionary themselves, then they don’t need licensing nor worrying about copyright. Probably using some mix between a frequency list and ChatGPT, ideally finally being checked by a human at the end. Copyright relating to content generated by an AI is currently a grey area / unlegislated in many legislations, from my understanding.
Or another potential way would be to scrape Wiktionary and modify it to be one line. From my understanding, you are allowed to use Wiktionary freely and modify it, if some sort of credit is given. This is the licence of Wiktionary:
I have mentioned it before, but I once imported parts of a Creative Commons licensed dictionary (CC-CEDICT Home [CC-CEDICT WIKI]) into Chinese Traditional. This was necessary because as one of the smallest languages on LingQ very few usable user hints existed. So LingQ would fall back to Google Translate in most cases, which is more of a hindrance than a help.
I would recommend more users do something like this, waiting for LingQ to provide a solution is probably futile.
Although I realize this process will be problematic in languages with inflections, as LingQ doesn’t deduplicate words and is unable to identify roots of words. So the number of entries could easily spiral out of control and having many LingQs brings a performance penalty, especially north of 100k.
The issue with Wiktionary is that it doesn’t seem to come in an easily usable format, afaik you need to download a Wikipedia dump (https://dumps.wikimedia.org/), those are gigantic and hard to process (afaik). This would probably require some technical expertise.
Another idea might be to use a popup dictionary software like Yomichan (FooSoft Productions - Yomichan) which allows you to bundle your own dictionary. I know this works well for Chinese and Japanese but I’m not sure about other languages. The obvious downside is that this only works using the browser.
For a second I hought you had meant you imported Wiktionary and was going to ask how you did it. I have tried this, as in most cases it is exactly what I would want for a smaller language without a larger community. But I ran into what you described – no easy way to get the data from Wiktionary, and if you can get the data no easy way to work with it.
Thanks very much for providing that link. This is actually perfect for a mass LINGQ creation process. I’ll look into extracting dictionaries for all the languages in CSV format.
@nfera Indeed, I don’t understand why there is no option for it and it is often not considered in other softwares either!
They could even buy and resell to us, so they would earn money as well. Or just give the option to buy the dictionary and take a commission.
However, dictionaries are usually more expensive than $10.
@noxialisrex infact, dictionaries are a big thing as they require a ton of time and work to be created. So LingQ cannot copy them or let us mass-copy them for sure.
But we upload a ton of content that it is private so why not giving the option to upload a private dictionary?
Even in simple csv database. We can buy the bilingual we want to and it’s done. We just import our private 100k words. That would be a MASSIVE time saved.
Honestly, this could be an option for resellers like Reverso or other brands too. They don’t have many options to sell dictionaries these days as everything is online, they could use this opportunity as well.
Yes. This is a problem inherit to community generated answers which I’m looking to solve. You could try my AutoLingQ extension, it auto creates lesson LingQs based on the most popular community definition.
Python is worth getting to know!
Even having it installed on your PC allows you to run helpful scripts like in the original post. You can avoid nasty website/exe implementations of the tools you need, and you are able to see the code in clean text so can verify yourself if anything malicious is happening.
This part is very true too, you almost become more invested when the answer isn’t available. But it still takes time away from getting through the content.
I’m open to suggestions regarding how a wiki generated LingQ should be formatted, its a bit challenging with the current UI restrictions and limits for the boxes. I’m thinking to leave the LingQs as they are and append all the necessary information to the ‘notes’ section of each word.
I’ve been going through the lessons, which I created lingQs with ChatGPT definitions. One thing I noticed is that even after my control for incorrect spelling/non-words, and then my quick manual scanning control, I still ended up importing several words with wrong definitions. Like I would read a sentence and not know a word and click on it. I could see from the formatting (and guess that it’s probably a new word for me) that it would likely to be from ChatGPT. This definition would then turn out to just completely not make sense in the sentence. I would then open up a dictionary and see that the ChatGPT definition was completely wrong. Like not even close… It didn’t happen too often. But I think that if people end up using ChatGPT to build a dictionary, you have to build in a process with more checks to avoid these mistakes. This would reduce the amount of wrong definitions.