Is chatGPT reliable enough ? Like is it really better than the online dictionaries ?
The problem for me is not that I have to create LIngQs but that it often takes time because the suggested translation is wrong. How good is chatgpt really ?
My current process for making lingqs is as follows:
Scenario 1: there is one or more community translation available and it is correct (in the current context). So I use that one.
2: 1 Does not work but the fallback translation of google translate that is automatically generated is good enough
3: Both 1 and 2 don’t work or are incorrect. In this case I check a popup dictionary. If I find a correct translation here I use that.
4. If 1, 2 and 3 do not work or give wrong results, I check the sentence in sentence mode and deduce the translation from there.
How do I know that with your script the definitions are correct ? Because it really depends on ChatGPT ?
Probably not. But GPT was likely trained with the data from a lot of dictionaries.
We are able to custom build our own AI these days. You could, for instance… if you had the time and money… collate all the dictionaries and wiki entries and books and film scripts and whatever and train it towards the most correct results. Probably with validation from a native, or tens of thousands of natives. A painful process.
We can work with the technology we have at our fingertips. GPT-4 and possibly Google’s AI may be more than capable of providing a good enough result to work most of the time…
I’m currently working on a project that imports wikipedia data as a LingQ selection (grammar, phrase and definition). Stay tuned on the extension page!
It’s accuracy would be language specific. Apart from different sizes of training data, some languages are just built differently, so may require different prompts. One of the things, which makes Italian challenging in this task is that one word can be many definitions, each with different grammatical usages.
Maybe another way is to bring the data in from Wiktionary, then run it through ChatGPT to re-write it in a way, which you like.
I would say there is a lot more English language data to sift through than there is Zulu.
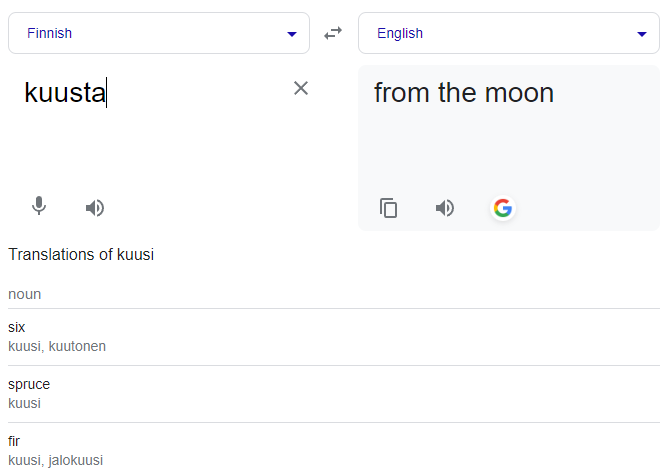
I think most language learners would be aware of root words and colloquialisms. Spoken versions of words contracting to the same root and without context you can guess but not fully understand. My solution to this is in the current implementation of LingQ Observer im showing word fragments from the text. I’ll use this data to find the grammar/definition of the word in relation to the context and apply this information dynamically to the LingQ. Say you clicked on the word ‘kuusta’ which is a common example in Finnish.
'KUUSTA' EXAMPLE
The LingQ would be created in relation to the fragment. This would make the LingQ for you as ‘Tree’ or ‘Six’ or w/e. The next time you see that word it will append the definition of the word in this context underneath and so on until you run out of characters for more edits.
This is just UI design. How do i display the information in a non scary way that is also extremely helpful?
So are you saying that every new encounter of a word that an individual tries to update the definition to take into account the context of the new word? Maybe I misunderstood this, because to me this sounds like a mammoth computing task. It would mean that every individual has personalised definitions based on every context they have encountered on LingQ. Personalised definitions for every individual, based on what they’ve read sounds like an epic idea. Is it possible and can LingQ handle this?
Another idea is to also provide a definition as ‘Definition not found’ to account for misspellings, etc.
Not as sophisticated as you think. Korean has 76 hints for 1 word as I was speaking to @jpp025 about in the observer post.
If several LingQ users have the exact same LingQ content i’m almost positive it combines these definitions on the backend. So you might end up with several LingQs with incomplete hints displayed with partial solutions to the word.
But we indeed just filter to show only your own encountered words definitions or the most defined LingQ. Whatever you want.