日语中这样的双引号,都会读出来,正常来说他们都不发音,只是停顿,现在却读出来了,请修正。
Thanks, we will have it fixed.
这个错误能否迅速解决?他影响了我日语的听力训练进程
Hello @lisanbao40 I tried to reproduce with brackets in separate sentence, with different voices and platforms, but it works well for me. Could you please provide more information so I can reproduce it. What voice do you use? Do you create audio from WEB or Tablet? If it is possible, could you also provide an original text (part of it) for testing?
这是我使用的声音模型,网页版和安卓版都是这个声音,我试过无论在哪里生成语音,都没有区别。
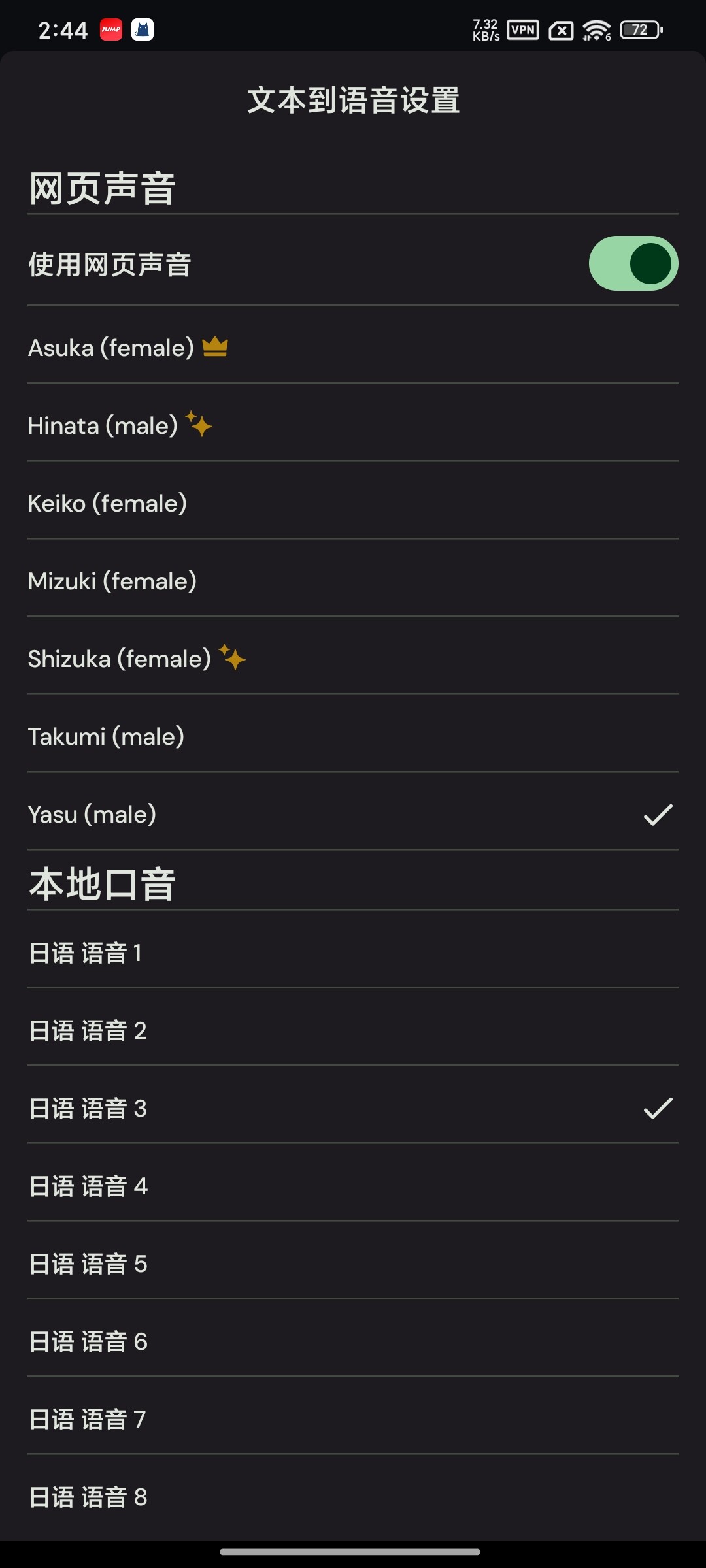
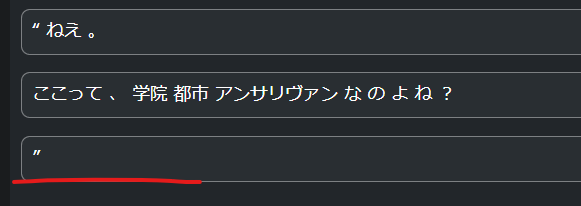
这是出问题的课程,在编辑课程的页面更方便查看它,你可以点击我标注的句子,倾听声音(就是最前面的几句话)他们会发出一句为(ダブルクォート)的日语声音
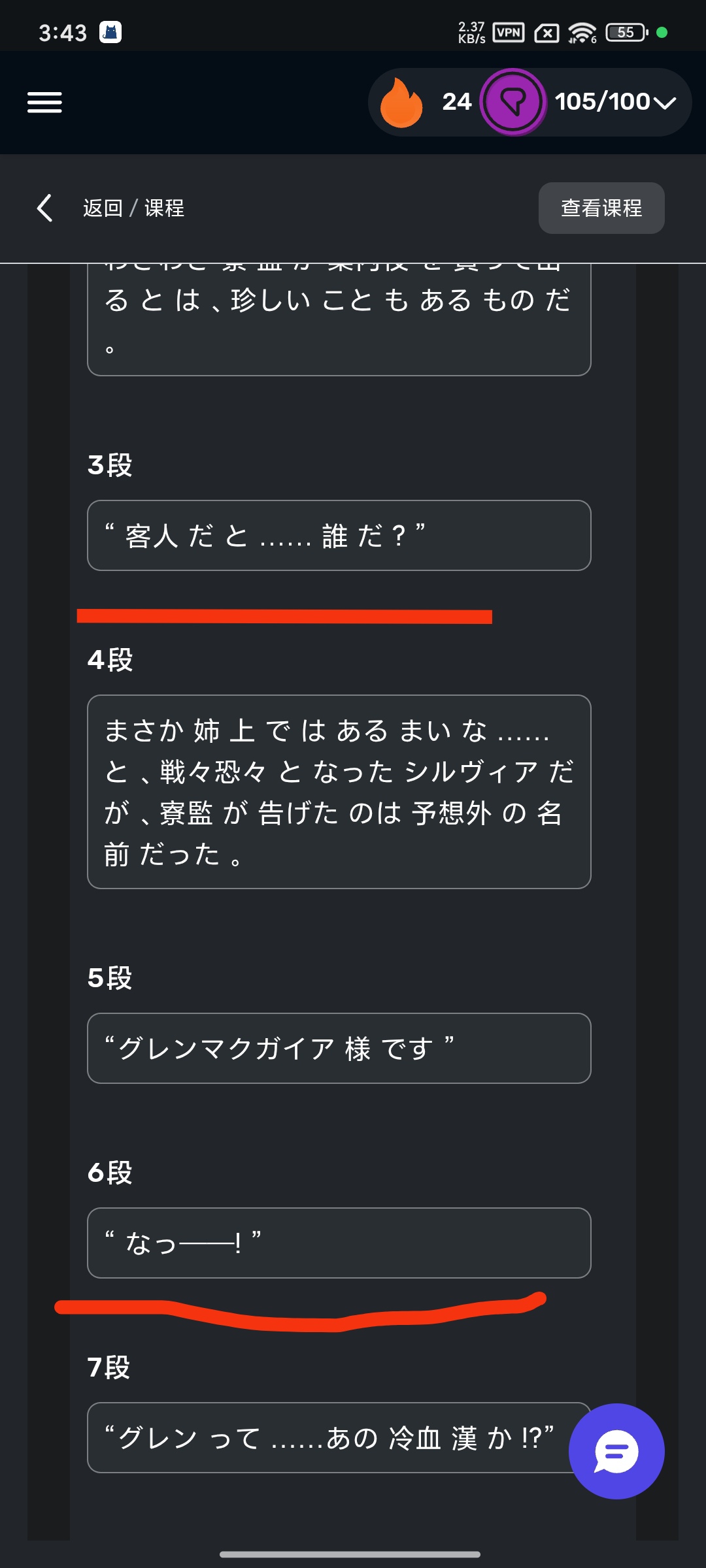
我换了个语音模型来生成语音,就是图中标记的Takumi,他没有读出双引号,完全是可以使用的。
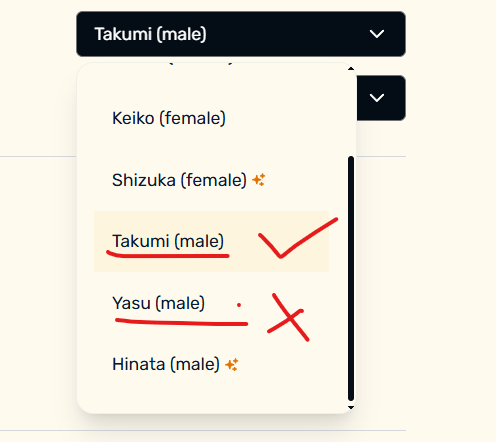
yasu这个语音模型会读出双引号单独为一行的句子,因为排版的不正确,导致这个双引号单独起了一行,所以它不得不读这个只有双引号的句子。
我新创建了一个课程,完美复现了这个错误,用yasu的语音模型生成,并留意双引号的位置,就会发现这个错误,登录 - LingQ
双引号单独为一行,这本身也是个错误,他会在句子模式中单独显示,我打算继续提交一个工单来详细说明。
@lisanbao40 Good to know that Takumi works fine. Thank you for looking into that. How those quotation marks appear in the separate sentence? Is it after file import? Is the original file like that?
Takumi and Mizuki should be fine for such lessons.
Keiko and Yasu may read the quotation mark.
原始文件本身是对话引用本身是「」的符号,因为这样的日文引号使用ai分割词汇会导致大量的符号错乱,所以我将文件中的所有「」符号使用软件修改为了正常的双引号,之后将文件导入了lingq。
最后的结果就是ai分割词汇功能正常,不会导致符号错乱,但是语音引擎会将所有单独一行的引号读出来。
原始文件是很正常的,引号的错误是导入以后出现的。
引号出现在单独的句子里,这应该和你们软件运行策略有关,所有带有句号问号感叹号的句子会单独为一句,然后将引号逼到下一行,我的建议是让带有引号的句子优先分为一句,这样可以大大优化排版,也不会出现句子模式单独一个符号的错误,你可以查看我另一个帖子,对这个错误有详细的说明
1 Like