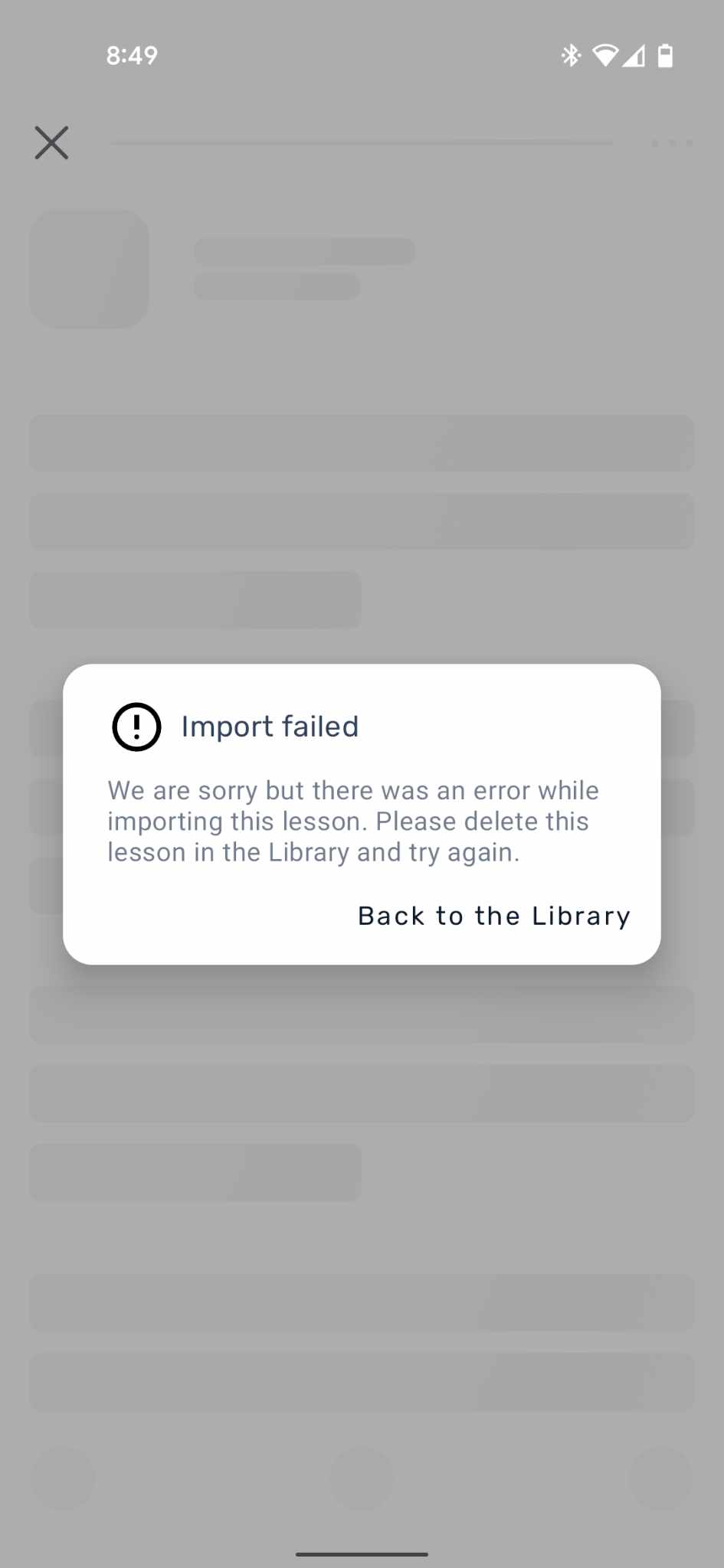
I have an eBook I’ve tried importing, but it keeps failing. I initially bought the book on Amazon and have tried importing the converted epub and txt files, but neither works. I also tried renaming the file in case there was an issue there, but no luck.
It starts off like it’s going to import and creates the first part, but never goes any further and when I eventually try to open it, I get a generic import failed message.
I’ve successfully imported other eBooks I’ve purchased from Amazon without an issue.
In the image, you can see both of the failed imports: one for the epub version and one for the txt version.
Thanks for the response @roosterburton. Looks like I’ll just need to email support. I tried both of your suggestions, but am still having the same issue.
I also tried importing a different book and the same thing happened. It was also purchased from Amazon and converted with Calibre.
I was able to import a different book via the same process just last week.
I can’t comment on its effectiveness. I just googled and clicked the first option.
I use this specific replacement for importing from Viki, because there are so many failed imports. It may help with your case too.
const text = 'yourimporttexthere';
const newText = removeUnwantedCharacters(text);
console.log(newText);
function removeUnwantedCharacters(text) {
// Insert spaces before each uppercase letter that follows a lowercase letter
let cleanedText = text.replace(/([a-z])([A-Z])/g, '$1 $2');
// Attempt to also separate consecutive uppercase letters used in acronyms or nouns
cleanedText = cleanedText.replace(/([A-Z])([A-Z][a-z])/g, '$1 $2');
// Convert HTML entities to their corresponding characters
const htmlEntities = {
'&': '&',
'<': '<',
'>': '>',
'"': '"',
''': "'"
};
for (const [entity, replacement] of Object.entries(htmlEntities)) {
cleanedText = cleanedText.replace(new RegExp(entity, 'g'), replacement);
}
// Remove emojis and some special characters, specific ranges excluded
cleanedText = cleanedText.replace(/[\u{1F600}-\u{1F64F}\u{1F300}-\u{1F5FF}\u{1F680}-\u{1F6FF}\u{1F700}-\u{1F77F}\u{1F780}-\u{1F7FF}\u{1F800}-\u{1F8FF}\u{1F900}-\u{1F9FF}\u{1FA00}-\u{1FA6F}\u{1FA70}-\u{1FAFF}\u{2600}-\u{26FF}\u{2700}-\u{27BF}]/gu, "");
return cleanedText;
}
It’s frustrating that I’ve received no response here from Lingq staff and only short responses via email asking a question that I had already answered in my original message.
Probably something like this could/should be implemented directly into LingQ as well. Maybe they have something similar? I sent them a couple of file some time ago, to check on those symbols, but didn’t receive any reply back yet.
I don’t use them anymore, I’ve finished those lessons but I’ll see with the next one I’ll encounter if the problem persist. In any case, they were ebook converted with Epubor, so I suppose the encoding they use it’s always the same.
For anyone who might come across this thread in the future: After @roosterburton tested the files, I realized importing failed during the “Optimize word splitting using AI” step. Going into the settings and turning that off by default allows me to import my ebooks.
I’m not sure what the difference in word-splitting quality is between the standard and AI-enhanced versions, however.