As far as I can tell, LingQ’s transliteration should be completely disabled, because it’s often wrong, and the text-to-speech engine can pronounce words correctly only when it’s disabled. Trust the voice, not LingQ’s annotations.
If you leave transliteration enabled, the voice engine is given the (often incorrect) transliteration, meaning you learn the wrong sound for kanji, potentially the wrong pitch accent or emphasis. (?)
Here is an example:

The transliteration is incorrect, it says “gai” but the proper pronunciation is “mochi”
In the sidebar I have intentionally disabled transliteration to force the voice engine to speak the original kanji.
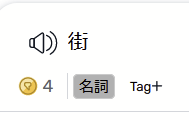
Pressing S says “mochi” which is correct, not “gai” which is incorrect.
Why does this happen?
When you press S to hear the word spoken, LingQ does one of 3 things depending on your sidebar’s transliteration configuration:
- if you have hiragana transliteration enabled, it voices the chosen transliterated hiragana, so the voice engine does not see the kanji, cannot pick the correct pronunciation
- if you have romaji transliteration enabled, it voices the chosen transliterated romaji, so the voice engine sees the roman alphabet and will even pronounce things using English rules, not Japanese, when it believes the word is English!
- if you have transliteration disabled, it voices the original text w/kanji. This produces the best results, as far as I can tell
I have already reported the romaji issue here: Japanese voice for words incorrect - #6 by cspotcode
Turns out, issues also exist for the hiragana transliteration.


