For a while I have been wondering about the number of unique words in each language (because this is what actually Lingq counts). On the Internet one can find the number of words that appear in dictionaries of different languages, but there is no mention of the number of “unique” words - that is when different forms of the same word are counted as different words (e.g. ball, balls = 2 different words). I am aware of the existence of the table that ascribes different levels to different word counts in different languages in Lingq, but I wonder about its accuracy. To put it simply, I want to know how many unique English words correspond to 150,000 unique Russian words. I am interested in this number, because I want set the same goals for different languages. But obviously in English there are going to be maybe three unique words for the word “ball” (ball, balls, ball’s) while in let’s say Russian there is going to be a lot more unique words for the word ball (мяч, мячя, мяче, мячи, мячом, мячами, etc.). So if my goal in Russian is to know 150,000 words, how many words do I need to know in English if I want to reach the same lavel in both languages?
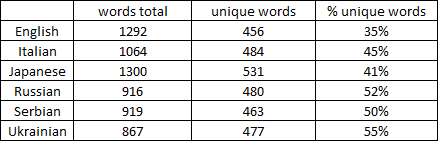
Well, I did my own research. I compared the total number of words with the number of unique words of the first two chapters of the Little Prince in the following lanuguages: English, Italian, Japanese, Russian, Serbian, and Ukrainian. Since Japanese doesn’t use space between words I converted the text into romaji with the use of Google Translate to be able to count the unique words. As expected, not only do these languages differ in terms of how many words they use to describe the story of the first two chapters, but they also contain different numbers of unique words. These are the results:
Slavic languages seem to contain considerably larger portion of unique words than for example English. I understand that two chapters of a single book are too small of a sample to call these numbers “exact”. Therefore I would like ask you for help if you are interested in this as well. Could we maybe try to come up with these percentages for all languages that are available in Lingq using a larger sample, let’s say 5 books?
English will have many repeated articles and prepositions where Russian will have no definite/indefinite articles and fewer prepositions. So what’s interesting to me is the number of unique words necessary to relate the same thoughts. I once read the results of some research that showed that speakers of different languages take roughly the same time to express the same thoughts regardless of the number of words and phonemes involved. The limit is the speakers’ ability to put thoughts into words, not the speed at which they can be uttered or understood; we’re probably all familiar with speeding up Youtube videos for quicker viewing.
For your project, we’re assuming good, accurate translations, of course. I’m not familiar with The Little Prince nor any of its translations. Sometimes translations might be a bit simpler than the original, and sometimes they are more correctly called interpretations that capture the essence but vary quite wildly from a word-for-word translation. This is probably much more so in literature and, hopefully, less so in diplomacy. Of course, word-for-word is never a good idea, but when comparing some translations with the original it seems as if the translator simply took the original as an inspiration while exercising his own artistic license. When choosing an English translation of The Master and Margarita for my wife to read I compared multiple English translations to find the one that most closely reflected my impression of the Russian original. None of them exactly matched how I would have translated the passages that I compared, of course.
Nevertheless, what you’re doing is indeed interesting. I wouldn’t be at all surprised if there were results from similar efforts to be found somewhere.
It’s a very interesting project. I hope you’ll keep digging and maybe using larger contemporary text. Indeed, the Little Prince is a tiny book, however, I’m surprise that the total words in English are so many compared to Italian. It has nothing to do with your research, I’m just surprise about that difference.
As @Khardy said, maybe there is already some research like this somewhere. If you find something about it I hope you’ll post it here so we can read it. And if you want to do some analysis on larger books adding some other language as French, Spanish or German, maybe we can give you some help. I have no idea how but you could ask here and maybe someone can help somehow.
This is something that came up when they were creating the “General Service List” in English which is the minimum number of “words”. The issue at hand is the definition of “what is a word”?
e.g. In english, “talk”, “talked”, “talks”. Is that three words or is it just necessary to know “talk”?
As far as slavic languages go (I only (barely) know some russian). I don’t think it’s hurting me that russian might have 15 declensions. I can still understand as long as I know the root. I don’t understand it perfectly but I have the gist of it. For me I am not bothering myself too much if there are variations of a word. I consider the russian word “known” if based on the “nominative”? word I can recognize all the rest.
You may have different standards and that might be what’s throwing you.
The issue sets in if your goal is perfect output and perfect understanding. Then you would need to consider all the various different declensions in the slavic vs the non-declensioning(sp?) languages like English.
Something to consider.
Actually I think we can disregard the declensions. What I had in mind was a comparison of unique words as they are defined by Lingq - that is, variations of the same word counted as different words. This is how Lingq counts your known words (unless you manually mark only the nominative form of your words as known or something). I am aware that a single word can have a number of forms in different languages because of plurals, declensions, tenses, etc. I know that it is technically a single word. However, the purpose of this comparison is not to rank languages in terms of richness of vocabulary, but to create a practical tool for users of Lingq to compare their ability of passive-vocabulary recognition in thier target languages. If it turns out that passive knowledge of 150,000 Russian words (as defined by Lingq) corresponds to let’s say 75,000 English words, then what this means is that in English one should aim for 50% of his or her passive vocabulary size in Russian in order to reach a relatively similar level of passive vocabulary recognition in both languages. It doesn’t imply that the Russian language is richer in vocabulary.
I remember someone asking here what the actual amount of known words, as they would be counted by LingQ, a native speaker would know. I didn´t answer that post but the fact of the matter is how many languages use compound words (German and Icelandic for example). For such a language, there are just about countless possibilities of combining words into different compound ones and native speakers would actually know countless words they haven´t ever even seen (crocodile-tear-gin-bottle-opener, bat-skin-hat-shop, oak-tablet-flipping-contest-prize-money…)
This is an interesting project and I would be interested in reading your conclusions when you reach them.
I understand the motivation to “know” a certain number of words in your target languages. But I think there is a simpler metric to use that will guide you to the same skill level in each of your languages: Number of Words Read.
While there will indeed be differences in “Known Words” based on “Unique Word Counts,” I think you could simply target the same number of words read.
If you are learning Spanish and Russian as second languages, and you set a target of reading 10,000,000 words in Spanish and 10,000,000 words in Russian, I predict your vocabulary in each language would be equivalent, even if the “Known Words” have a different number.
That’s not a bad suggestion. However, there is one more factor to consider - lexical distance. Here is an article about it including a useful diagram (A Map of Lexical Distances Between Europe's Languages - Big Think). With languages that are related to your native language (or even languages you already know) your acquisition rate can be expected to be much higher than with unrelated languages.
I am learning Russian, which is a related language to my native language. And although collective ranking of Russian learners in Lingq doesn’t include the “number of words read” statistic, based on the number of Lingqs other users created, it is obvious that I need to create much less Lingqs than other people to reach the same level of vocab recognition.
I expect the same to be true about the number of words read, which is why it might be a slightly misleading predective statistic. Assuming you are a native English speaker, if you read the same number of words in both Dutch and Hungarian you are likely to end up with a considerably larger passive vocabulary in Dutch than in Hungarian, because Dutch is closely related to English, while Hungarian comes from a completely different language family.
But given that we don’t have a better tool, I agree that the number of words read can be useful. Especially the further your get with you langauge learning, because lexical distance’s effect declines as your language skills increase.
That’s a good remark. But frankly how likely is it that a considerable part of your known words consists of " crocodile-tear-gin-bottle-openers"? But yeah. It is useful to understand that different langauges have different nuances and styles that can mess up the ratio.
’ But frankly how likely is it that a considerable part of your known words consists of " crocodile-tear-gin-bottle-openers"? ’ - well the more you would read a language like Icelandic or German in LingQ, the more of these compound words you´d see maybe once or twice in your lifetime would come up. I don´t think they´d be too much of a factor if you´ve read a reasonable amount of words. If you read dozens of millions of words and upwards, the higher the ratio of these rare words would become. Eventually, even the ultra-rare stand-alone words would mostly all become known and the only new words you´d get would be proper nouns (names of people and places) and these complex/rare compound words.