I really appreciate the way LingQ tracks known, unknown, and LingQed words in each text. However, I think the current stats could be even more useful with a slight shift in focus.
Right now, longer texts tend to show a higher percentage of unknown words. That’s because known (i.e. common) words repeat more often, while rare words keep accumulating. But this doesn’t always reflect how challenging a text feels to read.
Would it be possible to implement a metric that shows how many unknown words appear per sentence or what percentage of the actual text (in terms of total words or characters) is unknown?
That way, I could better judge how difficult a text will be to read in practice — for example, by estimating how many new words I’ll encounter per page.
This would really help in choosing content that’s at the right level for me.
You can see the percentage of unknown words for a lesson. Isn’t it enough?
It is not perfect (some content is much more difficult than one having the same unknown word percentage because of the narrative style and sentence structure), but it works well as a ballpark estimator of the difficulty of the content.
Little off topic but related. It would be cool to have like…a map of known and unknown words, with a grey area being words that are somewhat known fading into words that are completely unknown. Or like if words were tagged by overall category (society, science, crime, etc) and like a chart of which category you understand the best. Math Academy does these knowledge graphs for known concepts. I just like the visual of what’s known and what needs work.
You can set the state of the word from 1 to known (there are five options 1-New, 2-Can’t remember, 3-Not sure, 4-Learned, and v-Known words)
Also, unlike math, which has a somewhat hierarchical structure, words can not be categorized well except for technical terms. Also, I don’t think we have to intentionally learn the words from all the categories, because they expand naturally by the content you consume.
It’s a valid request.
% percentage is not normalized. You cannot compare percentage for text of different length.
10% of unknown words in a 5 minutes video is not equivalent to 10% of unknown words in a one hour video.
Let’s take this example:
Text 1 I am a man.
Text 2 I am a woman.
I don’t know words man and woman.
So in Text1 and in Text2 25% unknown words.
If I consider text consisting of Text1 and Text2, I have 5 words : I am a woman man.
Percentage is now 40% of unknown words. So it’s harder than Text1 and Text2 although the difficulty is the same.
If you have calculated as new words per word written, it would have been 2 / 8 so 25 %.
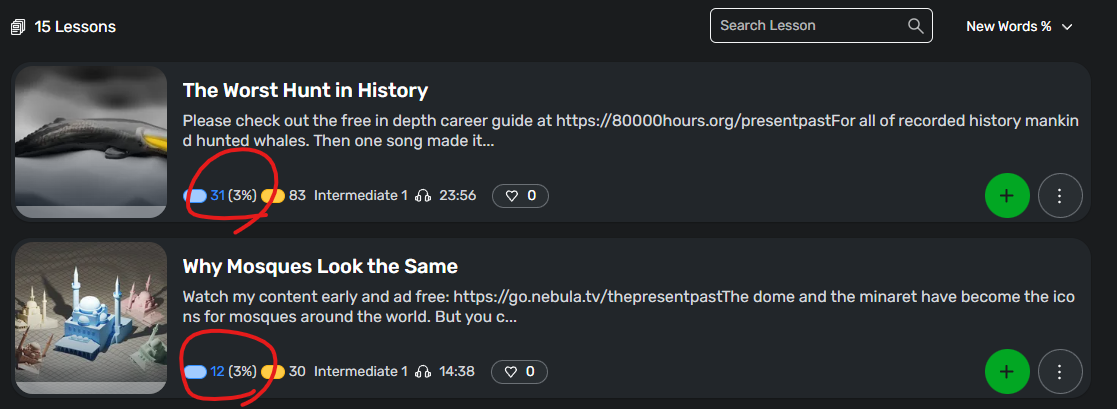
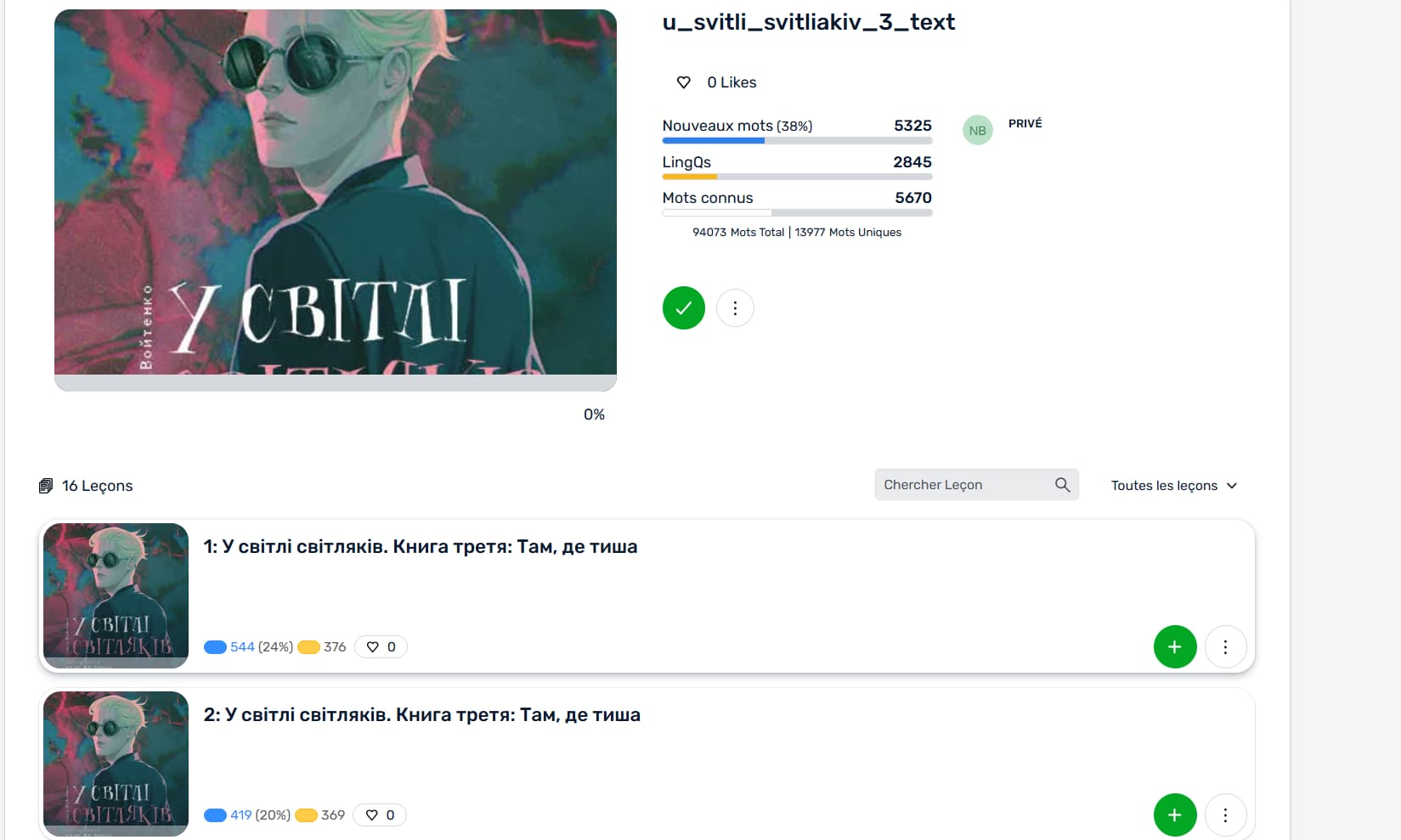
Book unknown quantity of words is 38% of words. So it looks quite hard.
But per lingq chapter we are talking about something around 20% which is acceptable.
Something I would also like is to have percentage with unknown words + yellow word.
Here I have even more yellow words than blue one. Difficulty is the sum of both as a small part of the yellow one with become known after having studied those lessons.
If you know that the percentage of unknown words will be higher for longer texts, can’t you just take that into account when judging the difficulty of a text? I am asking for a friend
Possible way to calculate: The lesson is divided into blocks of eg. 100 words. For each block, the percentage of blue words is calculated individually. The average of the percentages of the 100-word blocks is used for the lesson, and the average of the lessons is used for the course.
I developed the feature you want
It provides the ratio of LingQ and known word. Providing the metric like the # of unknown words per 1000 words, is not easy technically.
Thanks! That metric is definitely useful, but actually not what my original post was suggesting.
For each lesson we have:
-#words (e.g. total number)
-#distinct_words (e.g. how many distinct words there are in a given lesson)
-#distinct_unknown_words (that’s lingQs+unkown words or blue words+orange words)
-#unkown_words (total number or frequency, this means you count the words several times if they appear several times in the text)
I assume, getting the #unknown_words is the difficult part?
Because ideally you would simply calculate:
Percentage of text unknown = #unknown_words / #words (1)
The current metric is:
Percentage of text unknown = #distinct_unknown_words / #distinct_words (2)
(The #distinct_unknown_word are either LingQs or new words)
I honestly can’t think of a reason why this metric is relevant for a learner. (As was pointed out with examples by nicolasbrunel)
You do have the #words (total) because they appear as a metric at the beginning of each lesson. If you can’t simply figure out #unknown_words there are probably some ways to estimate them. I have been thinking about a solution to calculate #distinct_unknown_words, but I realized that it does require some math.
I am just unhappy with the current metric because of the given reasons. Having something like I wrote in equation (1) would be ideal. But maybe there is another solution.
Percentage of text known = “knownWordsCount” / “totalWordsCount”
Or what we are probably looking for:
Percentage of text unknown = 1 - Percentage of text known
I believe what it is currently calculating is:
Percentage of text known = “newWordsCount” / “uniqueWordsCount”
if I am not mistaken. And I don’t understand why you would calculate that.
Edit: I am not sure what “knownWordsCount” is exactly. If it is the total number of words you know in the text it’s easy, like I described above. If, however, it is just the general number of known words (in your account for example) or if it is the number of known unique words, it is not as easy.
But this is very similar to what we have right now. It will still increase as the text length increases.
I’ve been thinking for quite a bit about the idea of correcting it with some statistical scalar (like from a zipf’s law) but I can’t get it to work at the moment.
I will get back to this topic if I find a way to calculate it.