Embedding Visualization:
Unlike my expectation, unknown words didn’t make a cluster that is located far from known words. They quite well overlapped. (Black dots are known words, and colored dots are unknown words)
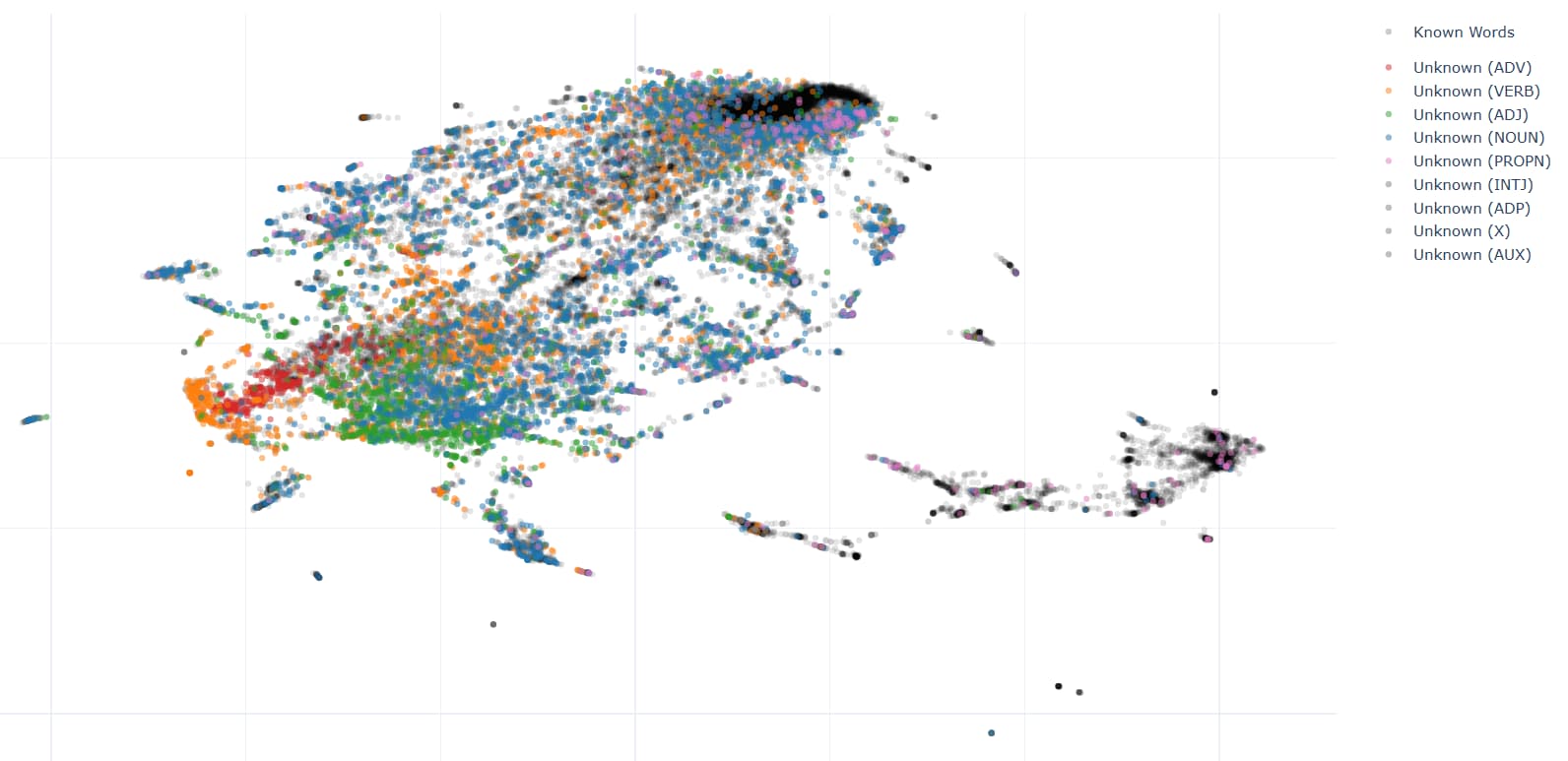
In the embedding space, words are quite well clustered by their topics. Except for some regions that have too diverse words, I can figure out the topic of the region by skimming the words located there.
This is a topic map I made.
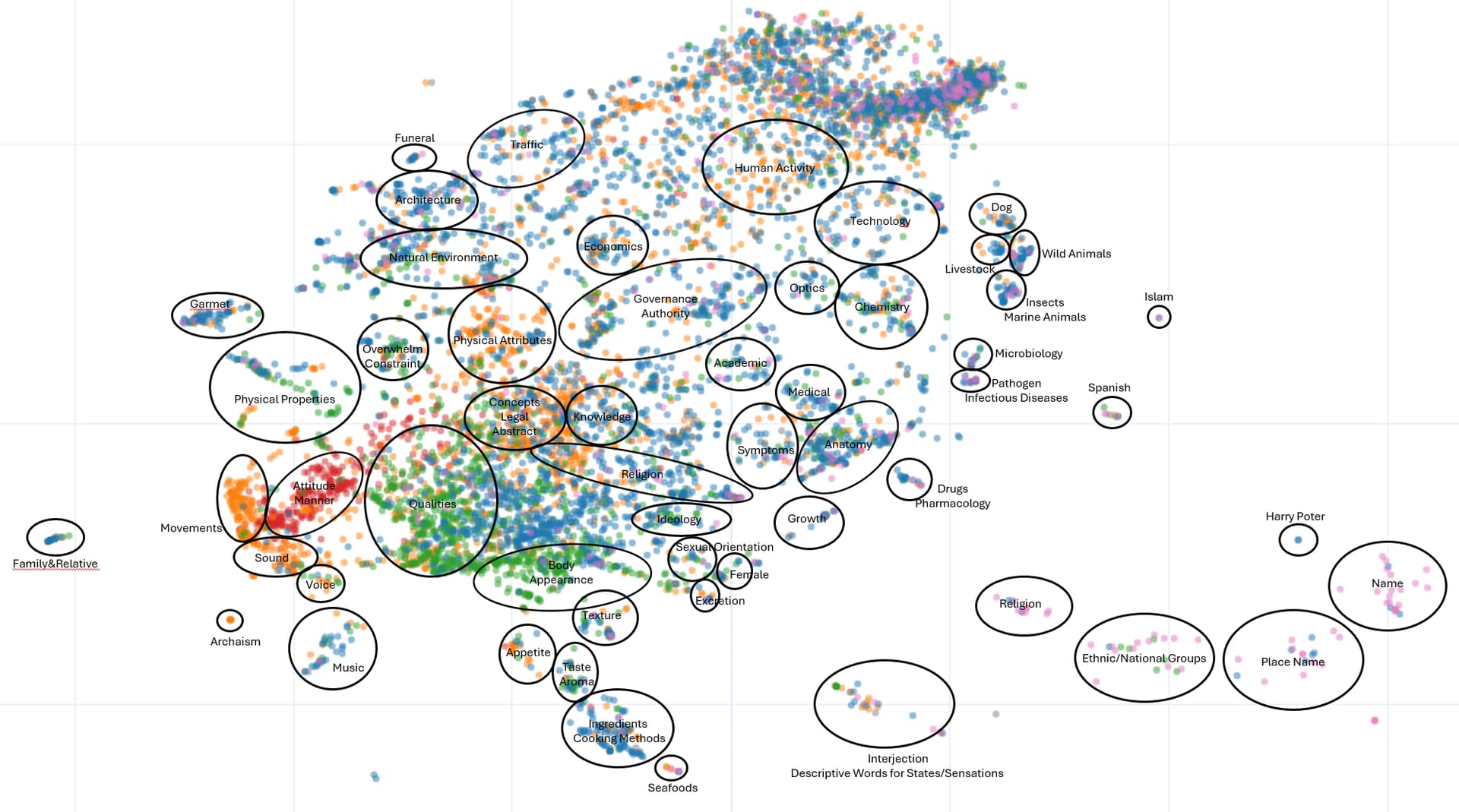
This is 10% of the unknown words plotted with text. You can see that the words are matched to the topic I assigned.

I’m thinking about how this info could be used for personalized learning.
Personalized vocabulary lists by topics?
Would it help learning to memorize words included in the same topic together?