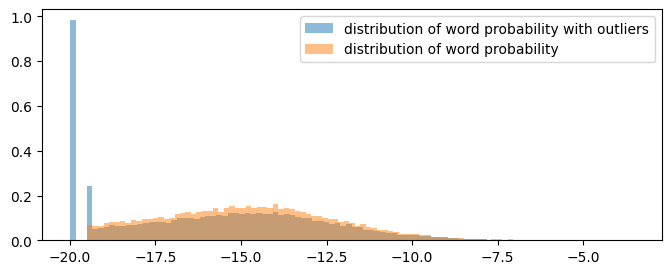
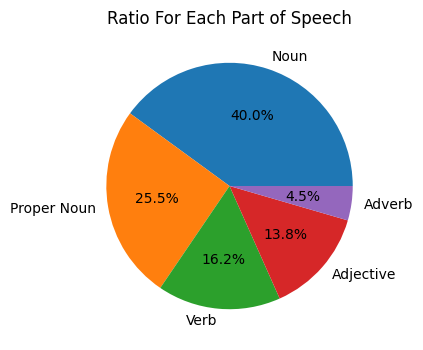
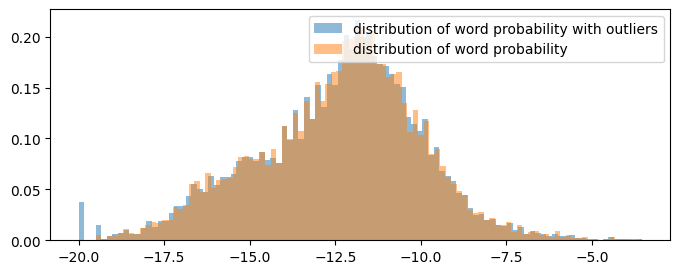
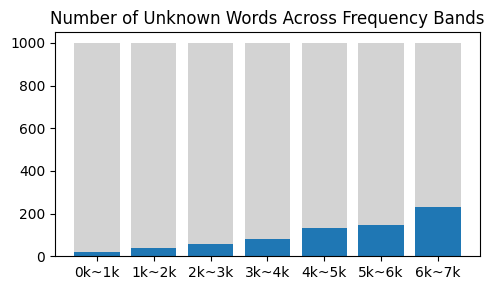
I’m still not sure how I can use this data for something useful for my learning. Maybe I can make a stat or visualization with a word embedding and LLM, but I don’t have a firm idea yet.
This is what I tried today
Downloaded all the known words (started from 41906 words)
lemmatized the words (e.g., Bones → bone, did → do, was → be) (30234 words left)
Removed non-English, broken, meaningless words (because I’m an English learner) (24393 words left)
Interestingly, there were so many non-English words (including words with typos or foreign names, etc)
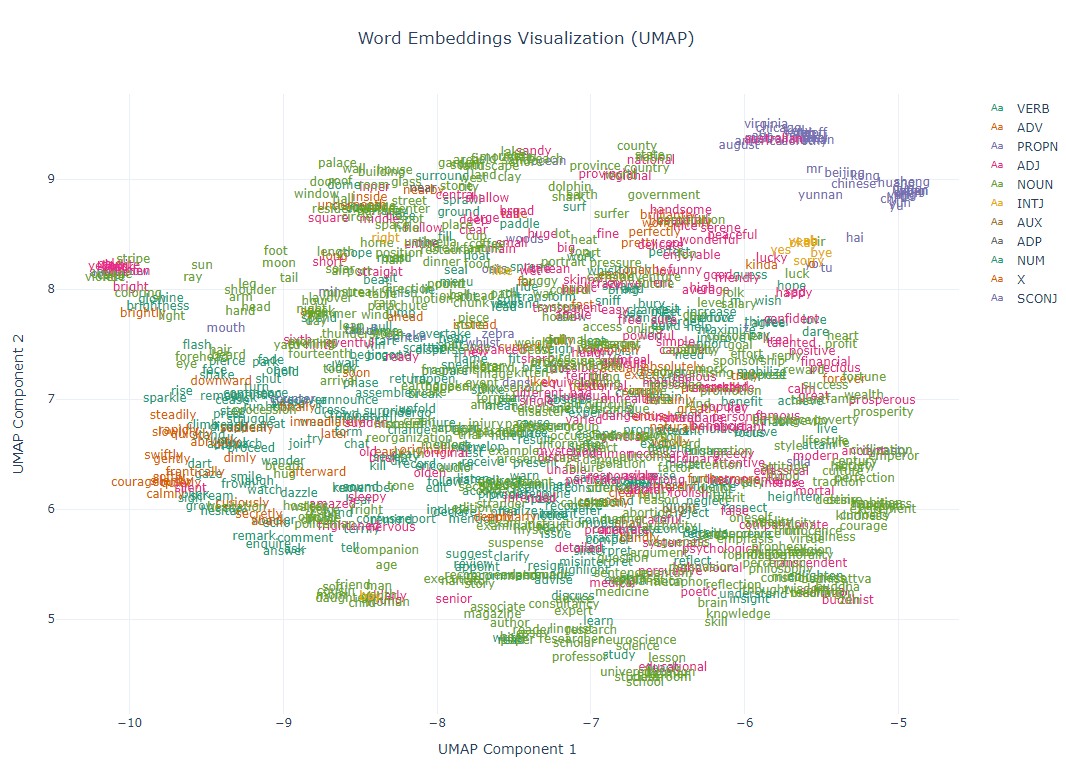
With the NLP tech, we can assign a vector to a word corresponding to its meaning. I used the vector embeddings of known words and visualized the vectors. You can see that the words have similar meanings and are located close together.
Sorry to say that, determining whether a word is valid or not, and finding the base form, is quite a challenging problem. I’m not sure it’s technically possible, considering users can import any content.
When a word is in a different alphabet to the target language, it could be ignored. URLs could be ignored. Perhaps a word could be ignored if it is not in the lingq dictionary. Proper nouns could be ignored etc.
That’s right.
It’s easier to think of the number as just a rough approximation of the number of words you know. It’s at least monotonically increasing. That’s all.
Interesting! I tried to export the words to excel once but they came out wrong(well maybe not technically wrong per se since its excels fault). Any spanish words with an Ñ, í, ü, didnt get written correctly.
I see value in analysing things in various ways as part of a broad and creative way to improve learning.
I’m interested in how to read more interesting things at a high level of understanding or
have a high understanding even if the text isn’t all that interesting.
Weirdly, the LIngq % isn’t ideal as it’s just blue words as far as I remember.
I’m learning Greek so text are moderately hard to find with some but limited supplies of interesting text / books at an intermediate level.
In a way, I’m interested in analysing the texts (books etc.) in comparision to my known vocabulary rather than my vocabulary.
Quickly picking high interest-moderately difficult text or some variation might need some analysis to support it.
Picking texts based on know words or semi-known words might be another way.
Mostly I just want to read but suffer in terms of vocabulary or interest.
And with AI, maybe we are near creating texts at a certain level of difficulty (possible) and at a target level of interest (I am less sure).
Which text can I read that is closest to i+1?
What’s the minimum number of words to learn to then know 95% of the text? Which text can I know 95% of the words by learning the minimum number of words?
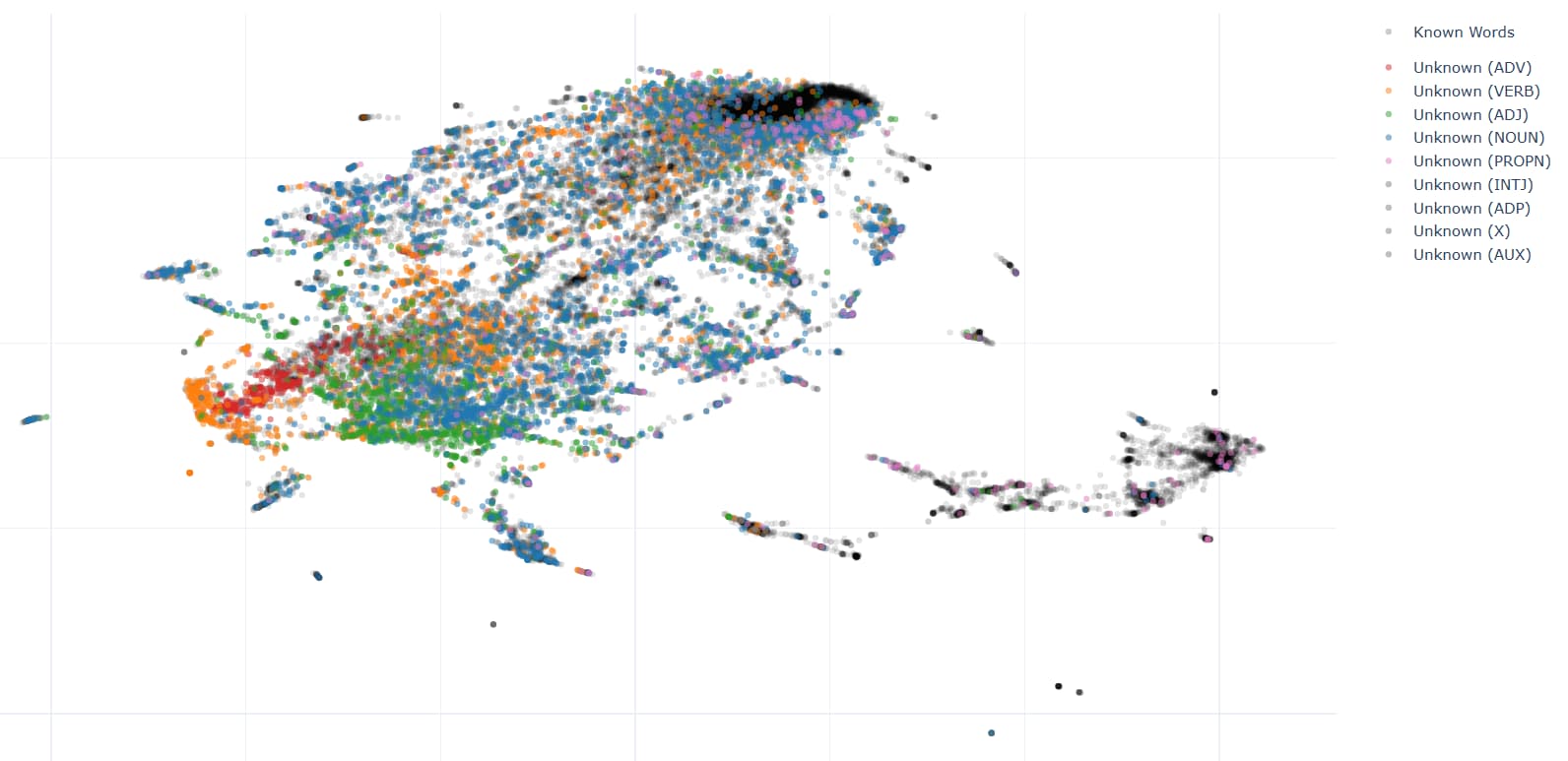
Unlike my expectation, unknown words didn’t make a cluster that is located far from known words. They quite well overlapped. (Black dots are known words, and colored dots are unknown words)
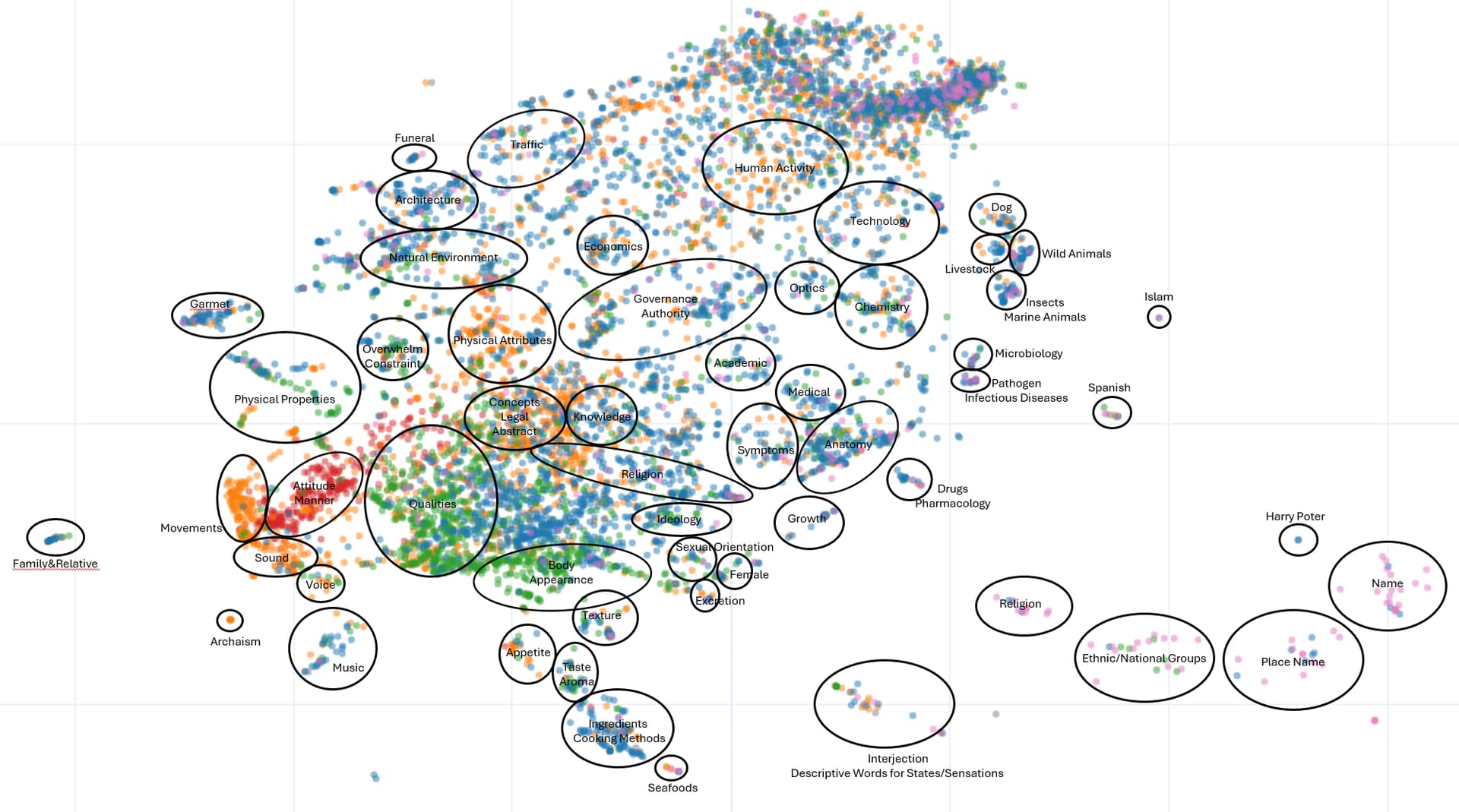
In the embedding space, words are quite well clustered by their topics. Except for some regions that have too diverse words, I can figure out the topic of the region by skimming the words located there.
Always nice to see more stats especially if I can sort my courses/books according to it too. If data from that stas can be used to generate a readability score for material we import that will be useful. A score enhanced, based on words we already know.
There is a grammar site https://www.kwiziq.com/ that has a mind map system. Your analysis and visualization remind me of that.
I like you have a Harry Potter topic circle in your visualization. That is one of my goal to be able to read that book in my TL. Your visualization will show me how close I am to be able to read it. This can be motivating. Maybe if it can even recommend me books/material to read in my library in an efficient sequence to reach that goal that will be good.