I had a stickybeak at the code for Netflix importing.
scriptElem.text = `
async function extractSubs(movieObj) {
let movieId = movieObj.movieId,
movieData = document.getElementById('LQNFXSUB'),
movieElem = movieData.querySelector('.id' + movieId);
if (movieElem) return;
Full LingQ Netflix Import Code
async function extractSubs(movieObj) {
let movieId = movieObj.movieId,
movieData = document.getElementById('LQNFXSUB'),
movieElem = movieData.querySelector('.id' + movieId);
if (movieElem) return;
movieElem = document.createElement('div');
movieElem.setAttribute('class', 'id' + movieId);
movieData.appendChild(movieElem);
for (const track of movieObj.timedtexttracks) {
if (!track.ttDownloadables || track.isForcedNarrative || track.isNoneTrack) continue;
const webvttDL = track.ttDownloadables['webvtt-lssdh-ios8'];
if (!webvttDL || !webvttDL.urls) continue;
const bestUrl = Object.values(webvttDL.urls)[0];
if (bestUrl) {
let text = document.createElement('textarea'),
lang = track.language;
switch(lang) {
case 'zh-Hans':
lang = 'zh';
break;
case 'zh-Hant':
lang = 'zh-t';
break;
case 'nb':
lang = 'no';
break;
case 'nn':
lang = 'no';
break;
default:
lang = lang.split('-')[0];
}
console.log('[' + movieId + '] Found', track.languageDescription,
'captions; code:', lang, '(' + track.language + ')');
text.setAttribute('class', lang);
text.setAttribute('name', track.languageDescription);
text.setAttribute('data-url', bestUrl['url']);
movieElem.appendChild(text);
}
}
}
async function extractInfo(url) {
let opts = new URLSearchParams(url.split('?')[1]),
elem = document.getElementById('LQNFXSUB').querySelector('.id' + opts.get('movieid'));
if (!elem) return;
let data = await fetch(url);
if (data.ok) {
let info = await data.json(),
title = info.video.title,
image = info.video.artwork[0].url,
descr = info.video.synopsis;
if (info.video.currentEpisode) {
search:
for (const season of info.video.seasons) {
for (const episode of season.episodes) {
if (episode.id === info.video.currentEpisode) {
title += ' S' + season.seq + ':E' + episode.seq;
image = episode.stills[0].url;
descr = episode.synopsis;
break search;
}
}
}
}
elem.dataset.title = title;
elem.dataset.image = image;
elem.dataset.descr = descr;
}
}
const originalStringify = JSON.stringify, originalParse = JSON.parse;
JSON.stringify = function(value) {
let orig = originalStringify.apply(this, arguments);
if (value === undefined) return orig;
let data = originalParse(orig);
if (data && data.params && data.params.profiles) {
data.params.profiles.unshift('webvtt-lssdh-ios8');
return originalStringify(data);
}
return originalStringify.apply(this, arguments);
};
JSON.parse = function() {
const value = originalParse.apply(this, arguments);
if (value && value.result && value.result.movieId && value.result.timedtexttracks)
extractSubs(value.result);
return value;
};
const originalXHRopen = XMLHttpRequest.prototype.open;
XMLHttpRequest.prototype.open = function(method, url) {
if (url.includes('metadata?movieid')) extractInfo(url);
return originalXHRopen.apply(this, arguments);
}
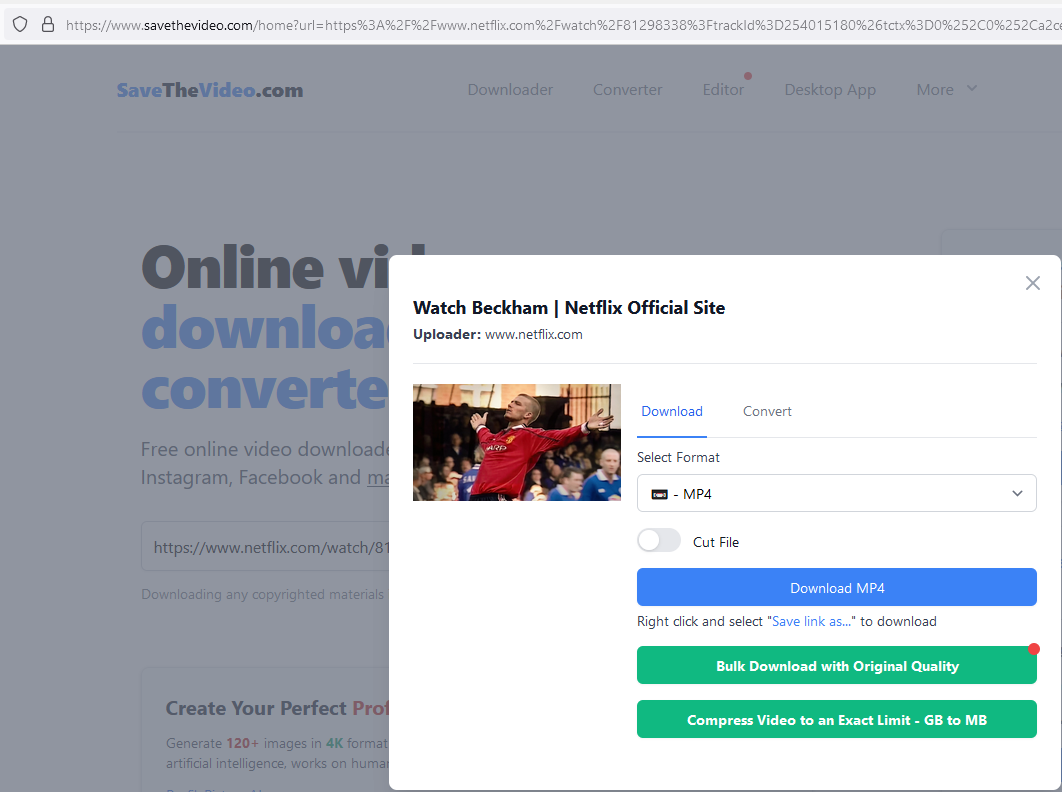
The big take away is that we need to find this element ‘LQNFXSUB’.
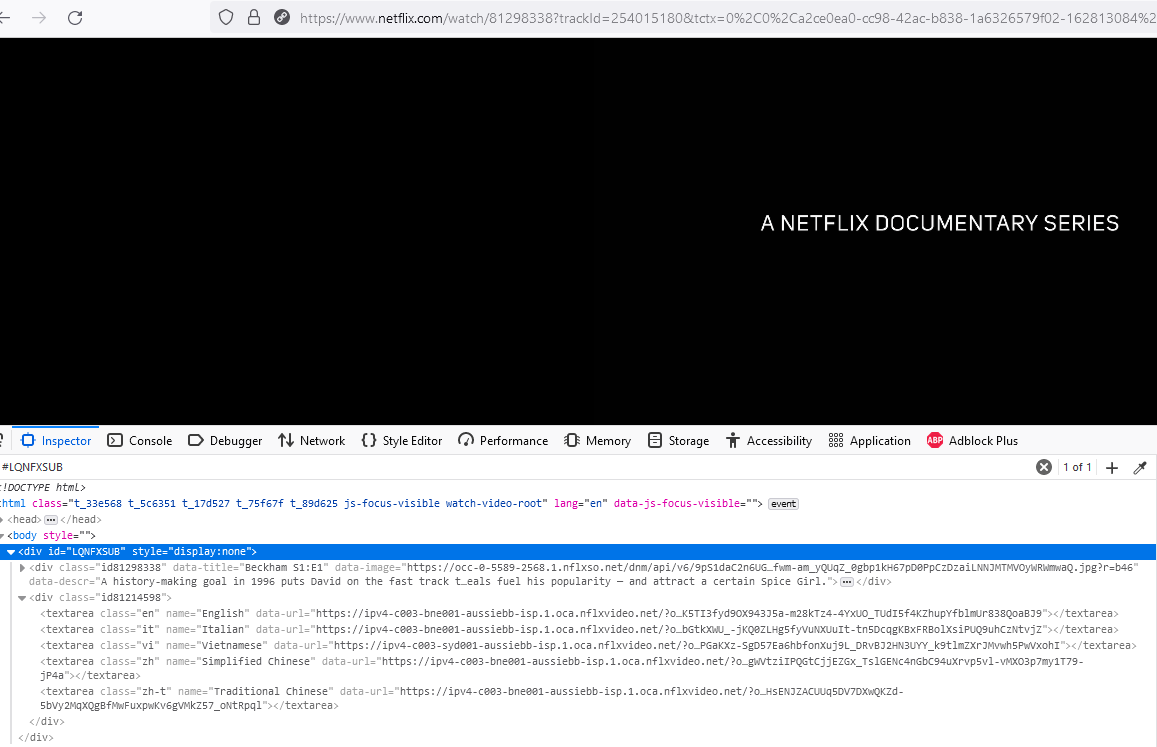
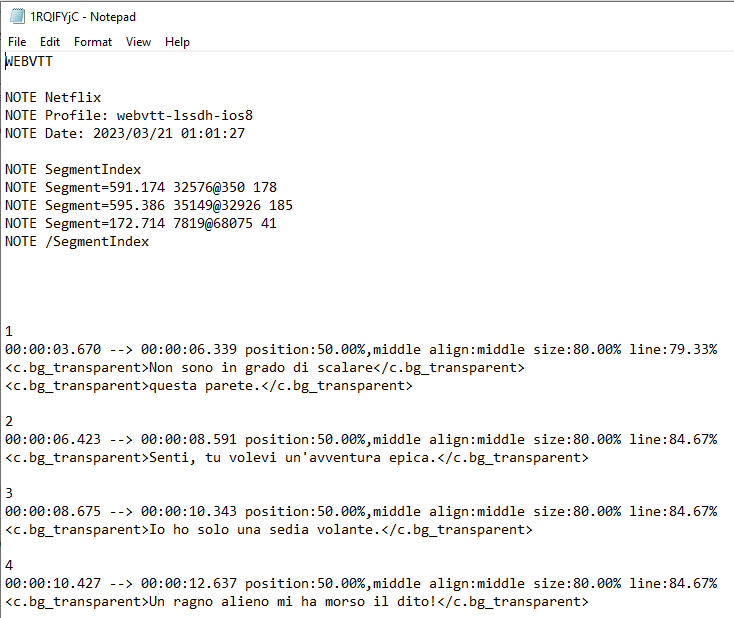
Subtitles are stored in this datalink

it ends up downloading with some extra info around the subtitles but that can be fixed with some formatting code.
You can also just copy the Netflix url to SaveTheVideo or Use my Rooster Import tool.