Hi there. I’m not sure about the exact process how LingQ handles YouTube importing of subtitles, especially for Korean. But I do know that unless subtitles contain punctuation, LingQ fails to accurately identify the ends of sentences. This means that sentence view always breaks long sentences up into sometimes-strange mini-units, and makes the sentence translation function useless.
Punctuation is not very common in Korean in general, and when people make even very accurate YT subtitles they often leave out the periods at the end of sentences, so this creates a consistent problem in Korean language YT imports.
Here is what a YT video with very good subtitles looks like when imported.
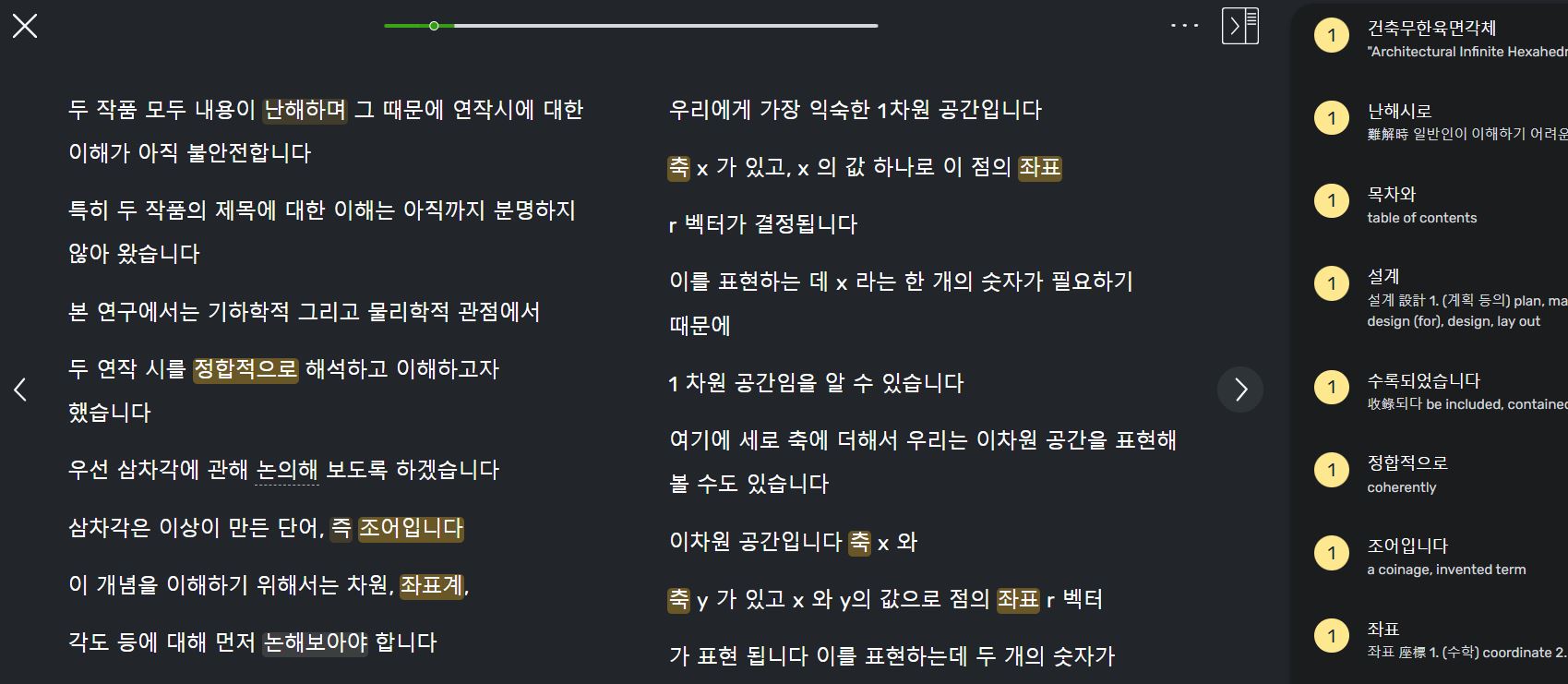
You can see that there are no periods anywhere, but any basic algorithm familiar with the language should be able to determine immediately that the “ㅂ/습니다” formal sentence ending demarcates sentences very clearly. (There is also the rhythm of speech, with natural caesura at the ends of sentences, which I think LingQ already detects quite well when matching audio to subtitles?)
Despite this, in sentence view each long sentence is broken up into weird units like this:
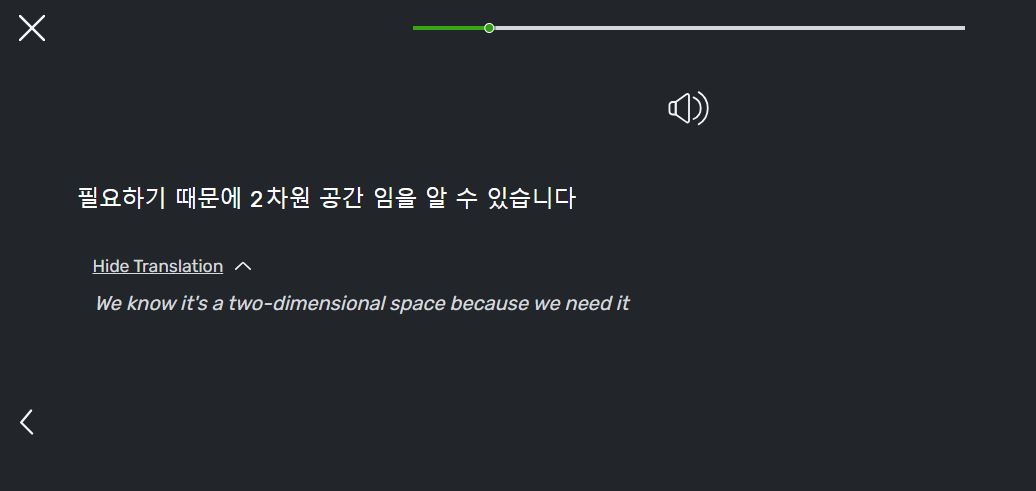
This means that the translation function is often misleading and incorrect, since subject particles, whole subject/verb clauses, and even single words may be broken up between units.
For those of us reading advanced material, I wonder if there’s some way that better sentence recognition could be improved when importing Korean? (and perhaps other languages, but I’m not sure whether this is a problem for other languages too.) It would certainly make sentence view useful again.
Thanks!