@zoran or others, am wondering if auto grammar tagging is going to be rolled out to more languages?
For those who don’t know what that is see this post here:
I have found that spaCy does an incredible job of analysing setences and words within those sentence’s grammar features.
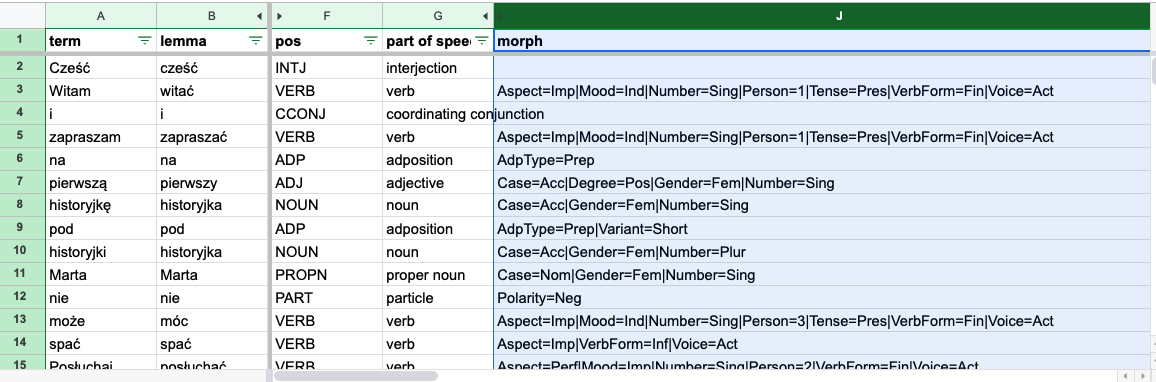
Here for example is a screen shot from a spreadsheet of info gleaned from running the tool on my lingq content. I can get info like:
the base form or lemma of any word, ie. the dictionary form of the word
the morphology of the word ie.
the gender of nouns, adjectives
the case of nouns
whether the word is plural
the person, tense and aspect of a verb.
etc.
Am thinking about how to create tools to use this data to enhance my and others lingq experience but what are the plans of the team on including more grammar analysis in the core product?
By the way is the existing grammar analysis done by spaCy or another tool? And which languages is it already available for?
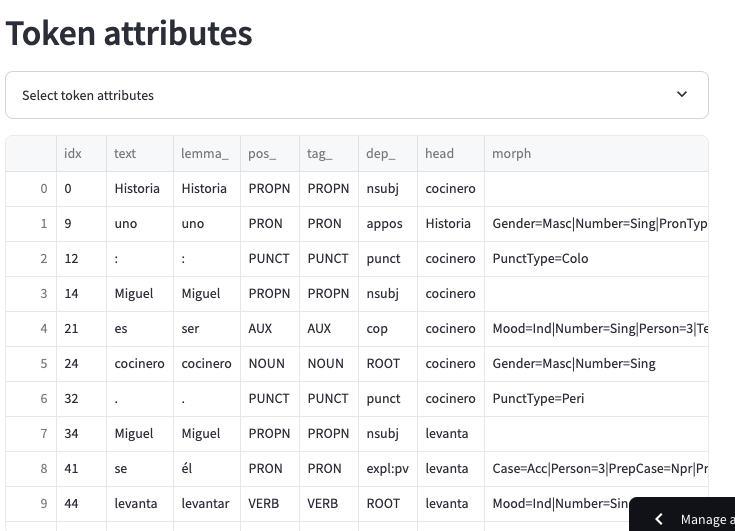
For anyone interested in how I fetched my lesson content from lingq through the api and than generated this grammar analysis see here:
The automatic grammar tags in Spanish are ridiculous. It gives wrong tags! Spanish words ending with -a or -o will be given tags as if it were a verb, which is of course not always correct. But also tags for tenses, nouns, adverbs, adjectives… are not applied correctly. It’s better NOT to have this autotagging at all if we cannot trust them. [This is one of the reasons why I seriously consider to NOT continue my subscription to LingQ]
Oh, sorry to hear that @Erik8970 ! How often are the automatic grammar tags wrong?
I have been experimenting with spaCy and it seems like it pretty reliably works to correctly identify lemmas and inflections for Polish. I did notice that the small models make occasional mistakes with verb forms for Polish.
I’d be very interested to know if you feed it Spanish and use the Spanish small model “es_core_news_sm” whether it makes mistakes as often as the automatic grammar tagging built into lingq does?
I’ve moved on to using large models for Polish and haven’t found any mistakes yet.
LingQ doesn’t have auto-tagging for German nouns as far as I know. It is actually a feature that I wanted to ask but not sure how they could do it.
It would be very useful if the grammar auto-tagging could do “der, die, das” for nouns.
Is spaCy able to do it?