This is why I would personally still opt for the actual book as a “transcript” if it is available.
A synchronized subtitle is not really intended to replace ebooks for R+L. It is just that, auto created subtitles.
This is why I would personally still opt for the actual book as a “transcript” if it is available.
A synchronized subtitle is not really intended to replace ebooks for R+L. It is just that, auto created subtitles.
can you pull the audio from youtube if it doesnt have subtitles? the extension just said no text found…
Agreed, but you have to admit, it’s a godsend for podcasts in the target language!
Oh I don’t disagree, podcasts, radioplays, TV shows, movies, even YouTube videos, it’s great. I’d just argue something is being lost with audiobooks depending on the adaptation.
You can extract the audio using any youtube downloader, for example 4K youtube downloader and download the audio to lingQ. Then you name the file and generate the transcript. I tried with Chinese and didn’t like it much. Besides the many mistakes, it gave traditional characters. Does anybody know if is it possible to select the output for simplified hanzi?
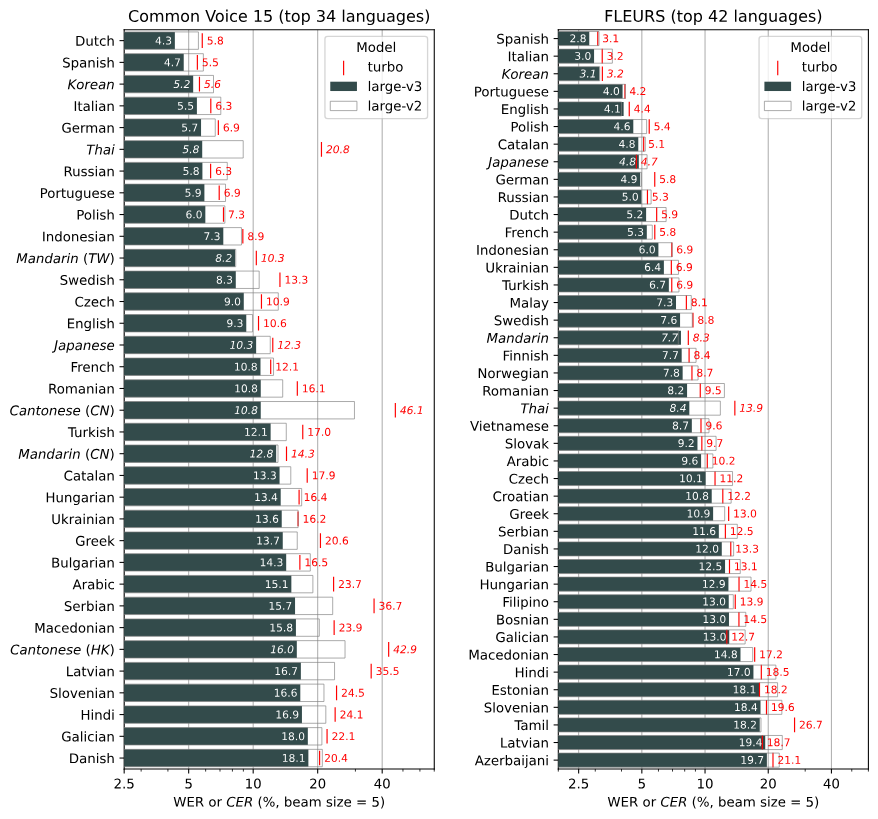
Yeah, that’s a known problem. Whisper doesn’t differentiate between simplified traditional (or even Cantonese) it’s all lumped together under Chinese. The model will just choose randomly, although I have definitely observed a preference for traditional characters.
To workaround this one normally includes an ‘initial prompt’, like: --initial_prompt 以下是普通话的句子。
This will steer the model in the right direction, it it is also helpful when one wants to indicate that punctuation is desired.
Unfortunately LingQ doesn’t expose this option and I fear they are oblivious to the problem. I can try to get their attention, but it’s always really difficult…
For now you could transfer the lesson to Chinese Traditional on LingQ and study it there → 3 dots top right when editing → change course.
Or use a traditional → simplified converter. The best one is probably https://opencc.byvoid.com/ but any other will probably do as well. You have to click ‘regenerate lesson’ first to get access to the full text.
Danke schön! ![]()
@bamboozled - If Whisper randomly chooses Chinese characters, could it not be directed to use a certain set of characters? We know that users importing into Chinese are looking for Simplified Characters. Can that not be specified somehow?
Absolutely, by using the whisper option ‘initial_prompt’. Providing a prompt that uses the desired character variant helps to steer the model in the right direction. This could either be exposed to users by providing another text field, or done sneakily by LingQ at the backend, e.g. by including some prompt containing simplified characters if the user is importing into simplified (for example: 以下是普通话的句子。). See the answer by ‘jongwook’ (Openai) for more info: Simplified Chinese rather than traditional? · openai/whisper · Discussion #277 · GitHub
This normally works for me, although there is always a chance that Whisper may ignore or forget this prompt after x hours or so. Also note that this prompt can influence the output, so choose carefully.
The initial_prompt option has other uses, for example if difficult to spell names or technical terms appear, you can try to give the model a hint as to what is expected. Here is an example: “The following is a conversation during a Dungeons and Dragons game, which includes NPC names like Zerthimon, Vlaakith, and Mordenkainen as well as place names like Agni’hotri, Tu’narath, and Niam’d’regal.”
Further, if the initial_prompt includes punctuation, it increases the chances to see output containing punctuation.
Another way to solve this is would be to convert the Whisper output to the desired character variant using a conversion software, like OpenCC. I think the ability to convert between them has been requested previously. This will definitely work in all cases, but there may be slight inaccuracies going from simplified to traditional.
The ideal solution for me would look like this:
@bamboozled - Ok, we’ll see what we can do there.
Hey @andrey_vasenin1 - super cool find with Whisper! I’m the guy behind Audioscrape.com, where we transcribe podcasts for pros, so I’ve been down this rabbit hole too. Your German SPIEGEL test sounds solid - 1.5 hours for 30 minutes on a basic laptop is pretty decent, and punctuation’s a game-changer over other free tools. Loving the excerpt you shared, it’s wild how well it catches the flow.
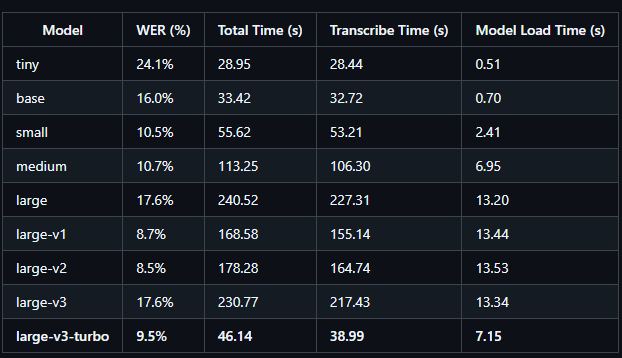
This thread’s gold - tons of great tips like whisper.cpp for speed (nice one @bamboozled ) and freesubtitles.ai for simplicity (props ericb100 and meddit_app ). I’ve messed with Whisper a bunch building Audioscrape, and it’s solid for DIY stuff, though like JanFinster said, setup can be a hassle if you’re not into coding. jmuehlhans , your uni’s use case with noisy field recordings is exactly why we went for a hosted solution - Whisper’s good, but it struggles with tricky audio unless you tweak it hard. For us, we’re at 92% accuracy on clean podcast audio, and we’ve got it running fast enough to monitor the top 100 U.S. business/tech podcasts in real time. rwsandstrom , your 80-85% on Chinese with the base model tracks with what I’ve seen - specialized terms (like JanFinster ’s medical stuff) trip it up unless you go big with the large model or fine-tune it. bamboozled ’s right - Whisper’s not smart enough to proofread itself, it’s just guessing chunk by chunk. If anyone’s looking to skip the DIY grind, Audioscrape’s built for this - transcripts, keyword alerts, all hosted so you don’t need a beastly GPU or terminal skills. TTom , it’s web-based, so MacOS works fine (no native app yet though). GMelillo , that Google Colab trick is clutch for free power - we lean on similar cloud muscle to keep things humming.
Thanks for kicking this off, Andrey - it’s awesome seeing how everyone’s tackling transcripts! Any of you tried Whisper on multi-language podcast episode yet?