Mine sentences (Michilini and Refold style) that are highly relevant to your conversational fluency.
Ask your Chinese girlfriend to train the parrot with the mined sentences (ca. 5 a day).
Et voilà, after 200 days, you’ll have a fully trained parrot with perfect (but limited) fluency in Chinese,
Of course, you should give it a break from time to time: let’s say 1 day off every 3 days. So the whole procedure will take a bit longer.
BTW, it would be good (to increase the dehabitualizing shock value) to include some interesting sounds like “doorbells”, “smartphone vibrations” etc. Hearing them, esp. in the early morning hours on weekends, could be an unforgettable experience, don’t you think?
However, I’m against mistreating girlfriends and parrots. Therefore, we probably need an AI for Chinese: a kind of ELSA SPEAKS MANDARIN (one with the correct CCP ideology and another one with the correct anti-CCP ideology).
Kudos to ELSA founder Vu Van, but we need something similar for as many languages as possible!
Ergo, a best-of-both worlds approach would be:
Let the AI take care of the big data.
Let the spaced-repetition-parrot take care of small data, i.e. sounds that really matter in our lives such as doorbells, smartphone vibrations (which give you the illusion of an Internet connection, even if the connection has just been interrupted), screaming boy- or girlfriends, etc.
And the next evolutionary step is probably not “Homo Deus” (Y.N. Harari), but “Parrot Deus” (the AI-enhanced version of the SRP).
However, the basic SRP-version is only for the so-called “free world”. For the CCP, there will be a “Parrot Deus” with advanced surveillance technology integrated.
“With language learning, and any “mental activity”, there needs to be some deliberate effort put in, at least if you want to get really good.”
Yes, if I translate this insight into my lingo then I’d say:
“Higher learning is always associated with (a bit of) discomfort.
Unfortunately, many people strive for completely effortless learning.”
“College in the US is where not learning effective methods haunts people.”
Same here.
However, it depends on the disciplines:
Having effective and efficient learning methods is a nice-to-have in the humanities and the social sciences. But it’s a must-have in the fast-paced IT world, for example. If you aren’t an effective and efficient learner in IT, esp. in SW engineering, you’ll probably have no future in IT at all.
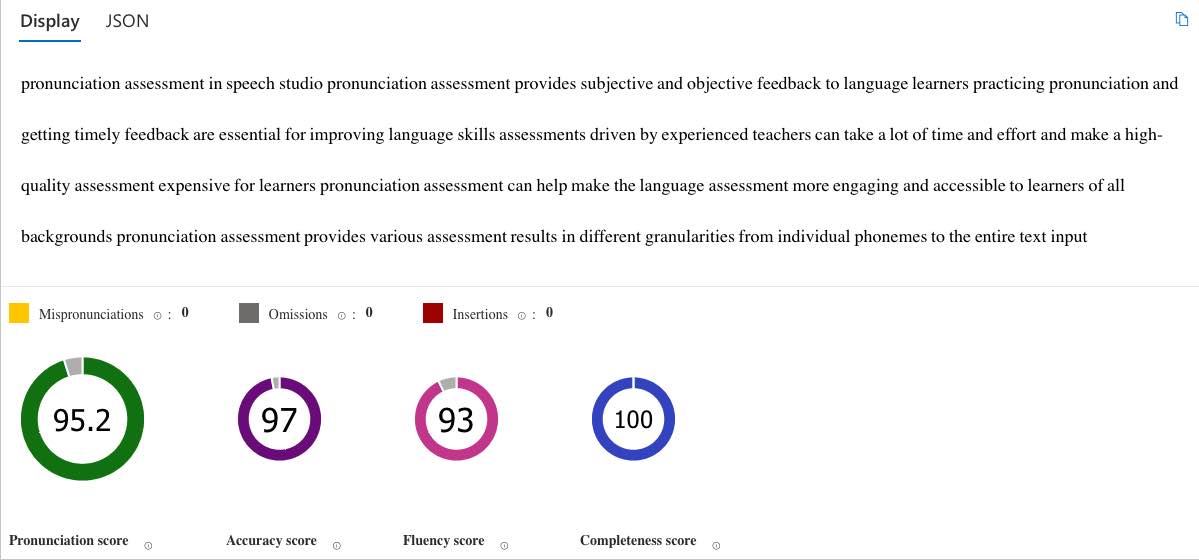
Has anyone tried such a pronunciation assessment service? I’m unfamiliar with Dell’s offer, but since I’m in the process of trying various transcription services, I have access to Microsoft Azure’s “Speech Services” which include a pronunciation assessment tool.
Follow this link for more information:
They have English (various), Spanish, French, German and Mandarin Chinese. I might give it a try tomorrow.
Would be good to know if such a tool could actually play a part in the language learning process.
Just to get back to you, I have tried it now and it works basically as advertised. All the important information is on the MS website already. For the purpose of demonstration I hesitantly offer my own example. Today being July 4th, I gave my interpretation of an American accent. Microsoft seems to think I did a pretty good job. But I would prefer if my pronunciation / accent didn’t become a topic…
The system breaks words down into syllables and phonemes, each get an accuracy score; the details can be found in the JSON file. To be perfectly honest, I don’t really know what to do with this information and how to act on it, but it’s certainly good to have it. The “fluency score” doesn’t get broken down, so I don’t know how that is made up, I did notice that I had to read pretty fast to get that number up.
Some limitations I encountered: the website “Speech Studio” seems to be limited in regard to the length of the audio, at least for me it didn’t process anything after 40 seconds or so. Annoyingly Azure accepts only uncompressed .WAV audio files. Those can get pretty big which combined with the German Internet results in long upload times, failed uploads etc. Maybe it’s designed for small inputs only? This system is probably best used via the API, if anyone is interested there are various code samples available:
@bamboozled
Thanks for testing Azure’s Speech Services and sharing your results / experiences with us!
We should definitely open a new thread for this topic where we can not only discuss other AI pronunciation tools, but also human-based pronunciation evaluations, for example in “Speechling”.
So I have been keeping up with this, around 5-10 minutes a day, and I still not sure how impactful it has been for me as I am not the best at hearing subtle differences in my own speech.
But… fun anecdote. I went to an æbleskive breakfast yesterday, and on the way taught my wife how to say æbleskive and a few sentences that may be “useful” (everyone speaks English). Well even in a 10 minute ride I could hear how much better her pronunciation was. Nogle was still the hardest by far.
The difference between this and simply shadowing or parroting was significant for her. With shadowing there was never any improvement I could hear, and I think the difference is forcing that time to think about what is being said/heard.
I haven’t listened to the podcast episode but from what I’ve seen in the comments, it appears to be a method also used by Idahosa Ness, that is, echoic memory. You guys should check out the Mimic Method (https://www.mimicmethod.com/). Some of it is a bit bland, but ultimately it has a lot of useful resources and it is free! His mini-course on Audacity was great and I am currently using some of his methods to approach Norwegian.